
所有的理论终将进行实践,终需产生价值,深度学习模型也是一样,我们学习研究深度学习的目的是减少重复的人工劳动,那我们可能要开始思考如何将深度学习模型运用在实际生产工作中。
深度学习部署步骤
我有幸加入了公司的人工智能部署团队,有完成比较多的深度学习专案运用,整理起来我们的专案导入一般要经历6个步骤,分别是拟定题目-环境准备-数据收集-模型训练-效能评估-上线运行,这6个步骤是深度学习部署中最基本的步骤,后面的四个步骤可能进入一个循环,比如说效能评估不能达到预定目标,那么返回到模型训练甚至数据收集上上,如果上线运行无法达到预定目标,依旧需要返回到数据收集和模型训练上,而一个深度学习专案的成功与否,取决于后面四个步骤中的方向,目前主要靠经验和尝试来找方向,接下来我们来详细说明每一个步骤。
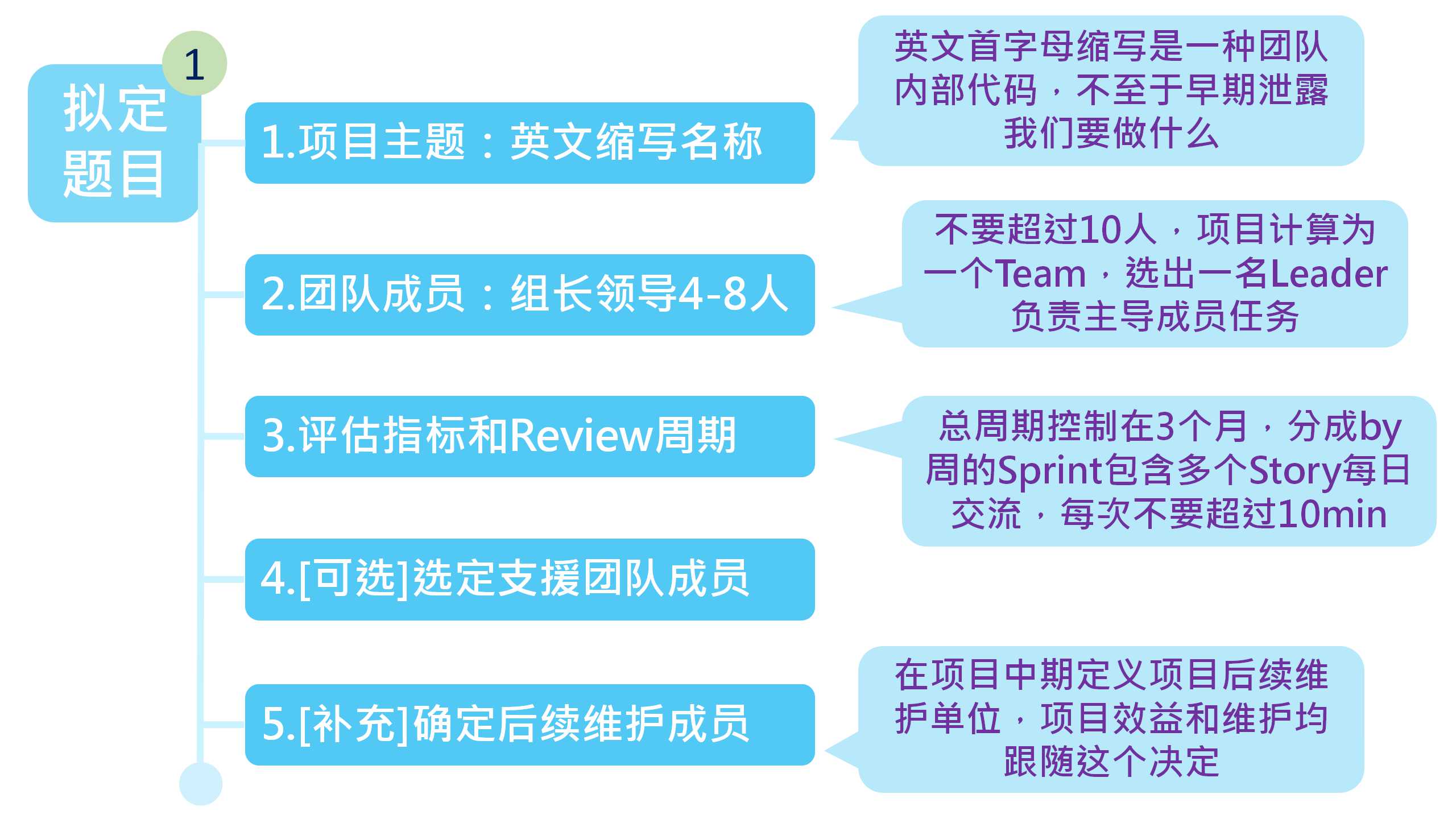
步骤1:拟定题目
这个步骤比较简单,但是却很关键,在这个步骤中我们需要设定一些项目的重要参数,我有列我们在项目中设立的参数来供大家参考
1.项目主题:呈现在大家面前的主题,一般是英文的大写字母缩写,比如我们想做产品外观检查系统,翻译成英文就是Product Appearance Inspection System,那我们可能就把主题成为PAIS,这样的好处是这个词语只有团队内的成员直到,不至于在立项前期就被竞争团队知道我们要做什么。
2.团队成员:单个项目的团队成员一般4-8人,不要超过10人,这个团队被成为一个Team,通过选举产生一名Leader(组长),团队成员中要进行工作执掌分配,对于特别大的项目,可以独立配置一组人员负责支援(一般公司叫做设备工程师,配置2人左右,负责搬运和环境架设等杂项)。
3.项目评估指标和Review(检讨)周期,根据我们呢的实际运转,发现项目周期一般在三个月最好,评估指标需要分成多个Sprint,每个Sprint再列出Story,每个Story再by天列出具体需要完成的项目,每日组长组织Review进度(每日最好不要操作10分钟,主要目的是询问成员有没有遇到什么问题),每周可以进行一次技术交流,每月需要检讨当前Sprint完成情况(主要是看项目的大方向是否符合之前设定的目标,如果有跑偏需及时分配工作纠正,时间最好不超过30分钟)。项目周期定位三个月主要是时间太短,大家很赶且不能完成,超过三个月时间太长,大家的热情被消耗,出现了混日子情况。
4.[可选]选定支援团队成员,一般大型专案中需要独立配置设备架设/维护人员,我们称之为设备工程师,如果条件允许可以配置一组2人的支援人员负责设备架设/调试/安装及检修。
5.[补充]确定后续维护人员/单位,这个项目再我们公司的项目中没有,但是我发现正是因为缺少这部分,我们的很多有前景的专案被迫停止,这是因为一般项目团队都是由多个部门的成员组成,在完成专案后各位主管将这次的项目汇报通过后就没有人愿意打理这个项目,各位主管就开始抢着在高阶长官面前表现自己,直接提前汇报了这个项目,导致专案最终算在A主管的头上,但是需要B主管来进行后续维护,时间一长B主管会不乐意直接停止项目维护工作导致了项目终止,归其根本,不是说A主管由多不要脸,也不是说B主管有多不尽责,因为从大体上看他们的做法都没有问题,因为他们都是项目成员的主管,所以我这里补充这一条就是提前定义好这个项目最终的维护方,维护方可以拿到这个项目的效益汇报,这件事情不一定要在项目早期进行,可以选在项目中期,不然部分部门会因为最终维护和收益单位不是自己而提前推出。
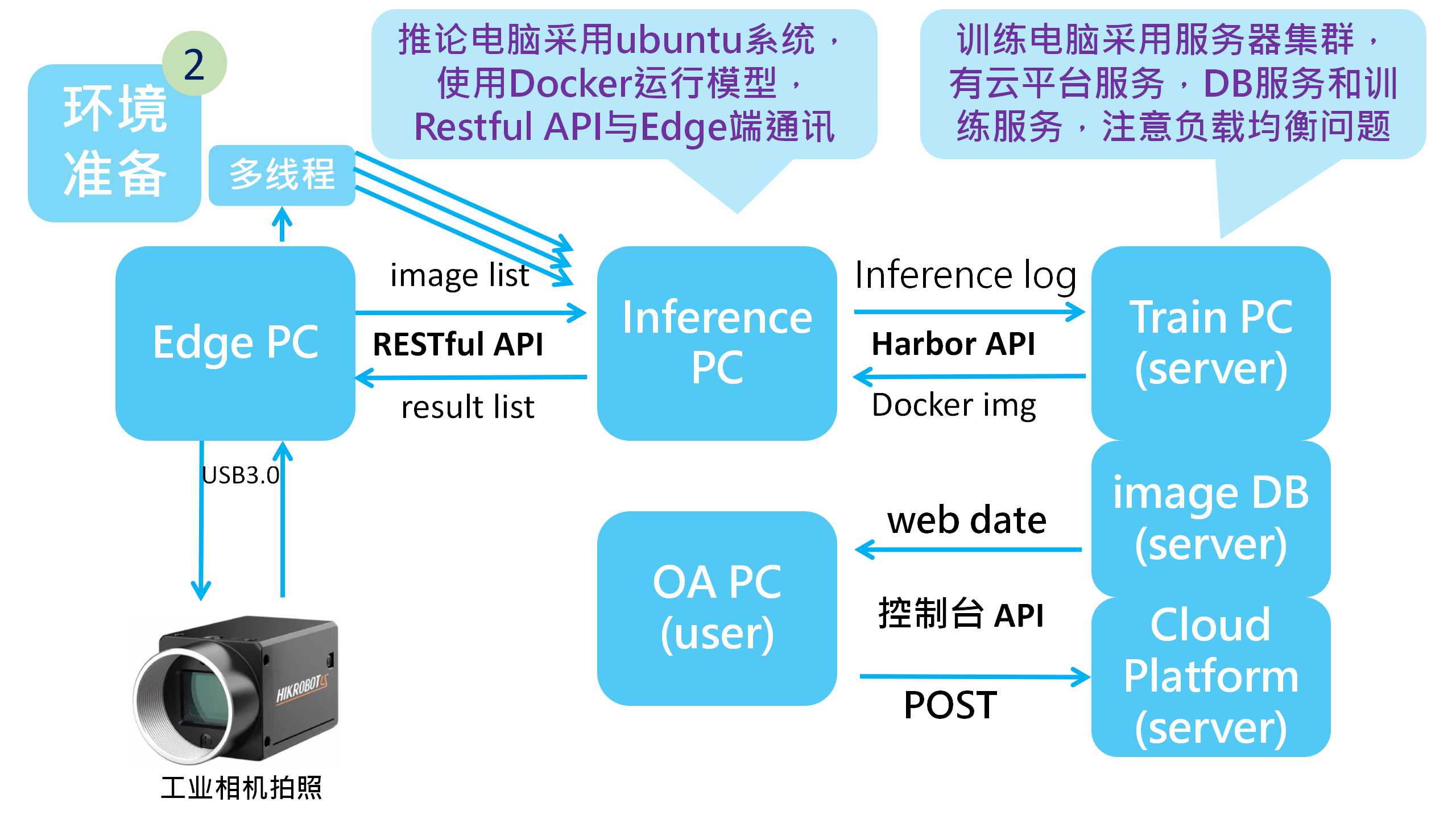
步骤2:环境准备
这个步骤一般可以请支援团队进行协助,而主要团队成员只需要进行数据调查和规划,需要确认的内容如下
1.确认需要的硬体设备,完成一个深度学习环境一般需要三个部分,分别是Edge PC,Inference PC和Train PC,其中的Edge PC需要能够运行程序,一般采用windows系统,需要配置摄像头,串口设备;Inference PC一般采用Unix系统,我们采用的是Ubuntu,安装python及Cuda等环境,负责将Edge PC 传送过来的图片进行推论再回传结果;Train PC指的是训练平台,可以看作是一台服务器,兼顾着数据分析和版本迭代控制服务器的角色。值得一提的是Edge PC和Inference PC可以采用RESTful API进行通讯,深度学习模型使用Docker进行封装和下拉,使用Harbor进行版本管控。
2.边缘设备准备,比如网线,摄像头,机械手臂等等,这些设备一般都是请支援团队进行部署,而团队成员需要根据自身的项目目标决定部署的为止,顺序和检修周期。这里值得一提的是摄像头部分,机器视觉的成果很大程度上取决于摄像头成像情况,在选择之前请考量我们要检查的对象来选择镜头和摄像头,一般如果要检查比较精细的产品则需要选用工业相机,如果产品检测面积比较大则选择广角镜头,还要配置相应的抗畸变镜头配件和平行光源。
3.产品动线设计,这里的设计不仅仅是单纯从产品角度来设计,而是要考虑协同部分,比如我们的设计CT是8秒,但是下方有一个移动平台需要26秒,而我们的总CT定义是30秒,那么我们需要有一部分协同作业,因为图像获取只需要1秒,其他时间可以移动,那么就可以将总8秒时间分成1+7,1秒拍照,其他时间协同移动平台进行作业,最后给移动平台一个信号来说明移动方向。
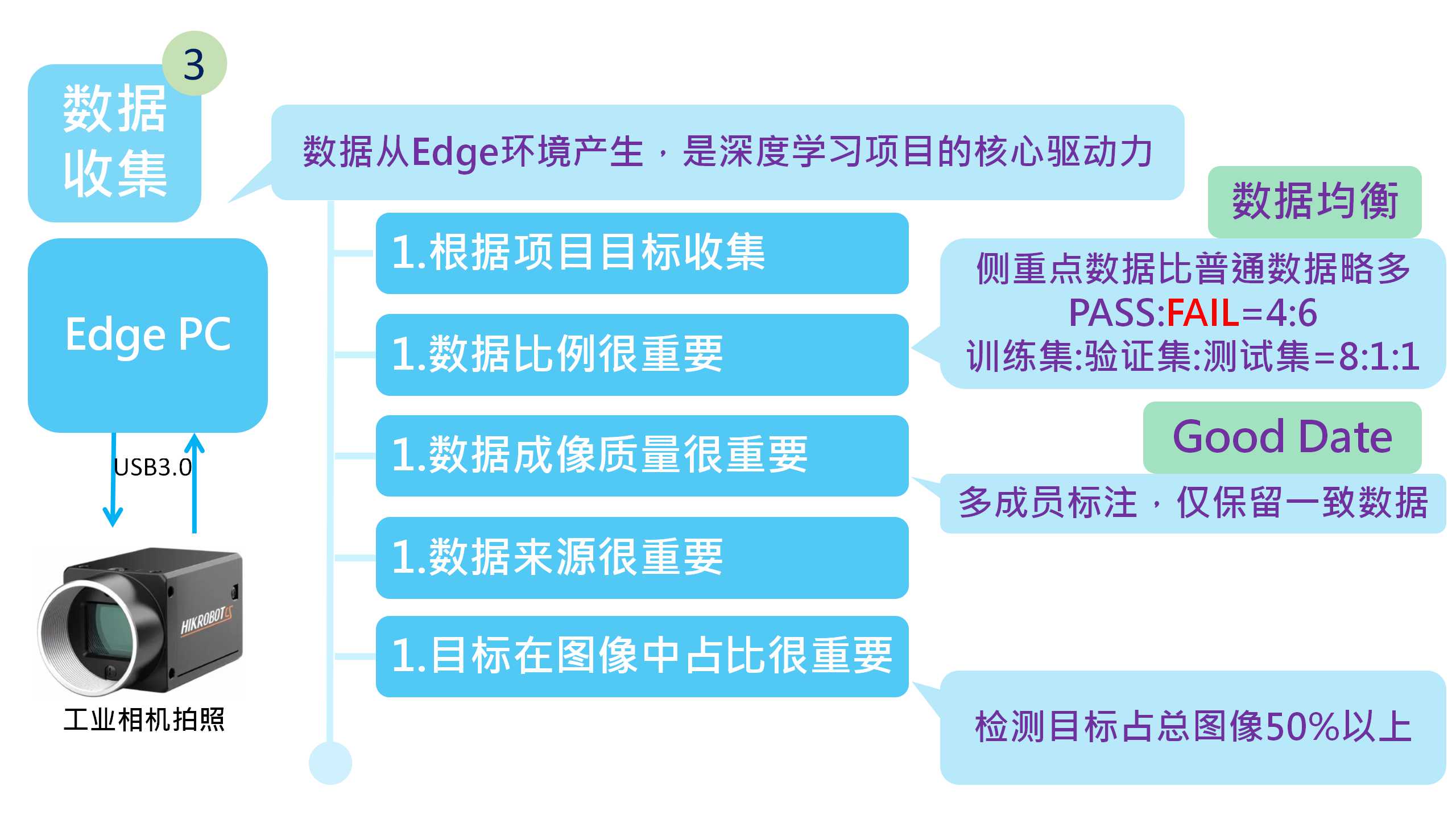
步骤3:数据收集
数据收集是深度学习很重要的一个环节,如果收集的数据有问题,那么后面所有的工作可能都是无用功,最终需要回到这个步骤,我们要明确一个核心:“数据驱动人工智能”,人工智能离开了数据基本知识一个逻辑框架,不具备实际意义。
1.数据收集根据项目目标来进行,如果我们的目标是判定产品有没有外观,那么我们就需要将目标转换成“AI分类运算”,输入就是产品的外观图片,输出就是“外观PASS”和“外观FAIL”,但是我们很可能会遇到一个问题,一次将完整的图片传输给Inference PC推论可能会遇到时间过长的问题,解决方法就是多线程,将一张图拆成以224*224为单体的小图,分8个线程同时传送ID和图片给Inference PC推论,然后以ID区分进行图片拼接成完整的结果。
2.数据收集比例很重要,不是说你实际上PASS比较多,你就收集PASS多,而是要以目标和模型的角度去考虑,比如我们的目标是卡关“外观FAIL”的图片,所以我们的关注点是FAIL的部分,那么我们的图像比例应该是FAIL偏多一点但不能太多,比如60%的FAIL+40%的PASS是常用的数据集组合,如果有多个分类情况依旧遵循这个原则,这个原则在深度学习项目中称之为“数据均衡”。
3.数据的成像质量很重要,在整理图片的时候,难免有标记错误的图片,比如说将PASS的图片放到了FAIL里面,这样训练出的模型会不够精确或存在未知bug,而我比较建议的解决方法是2成员进行标注,然后取两个同仁标注相同标签的图片作为数据集,而标注不同的部分,直接舍弃。但是大家可能还会遇到一个问题:模型训练的结果经常误判!这也是我们经常遇到的问题,于是我们又做了一件事来解决这个问题,就是让剩下的成员通过人眼观察前两位成员标注好的图片,看是否可以判别出标签,如果觉得模糊或难以判别的图像,均舍弃掉,注意这里是每个人都要看所有的图片。而这个概念正是深度学习中“Good Date”概念。
4.数据的来源很重要,在获取数据集时,不要为了自身方便,而将主观认为同类型的数据添加到数据集中,这样做的结果是有效数据被稀释了。我们的一位成员做30类判定项目时曾经因为老师说图片数量是影响模型效能的一个重要因素而将A线的图片做了10倍的数据增量(主要通过偏移,旋转,调整亮度等方式增加数量),甚至在最后还觉得数量不够,从B线抓取了部分数据添加进来,认为这样能够让模型更加聪明,最终数据集的数量到了37万图片,而驯良模型花费了2天,模型始终不收敛,最终保存出的模型效能低于80% ACC(花费200张图片的效能大概是85% ACC),最终在总部的各位同仁帮助下,数据集从37万张赛选到3万张,模型效能99.5% ACC,这个概念其实也是深度学习的“Good Date”概念。
5.需要检测位置占推论图像的比例很重要,在我们标注过程中,尽量选用判定清晰,检测目标占比大的图片进行训练,比如一张图片是224*224像素的,如果你的目标低于图片比例的50%(25088px),那么你的模型可能学到的东西并不是你希望它学到的,特别是图片构成比较复杂的时候,我们可以使用CAM(热力图)来查看图片的注意点在哪里,我们曾经训练了一个很成熟的卡关排线接口类型的模型,其效果另大家都很满意,直到有一次因为设计原因修改了接口所在的主板走线,我们发现模型似乎没有那么准确了,在排查了光线、焦距、移动速度等参数后,我们使用CAM才发现,原来模型一直在依靠主板的走线在判断接口类型,根本不是我们想要教模型学习的地方。
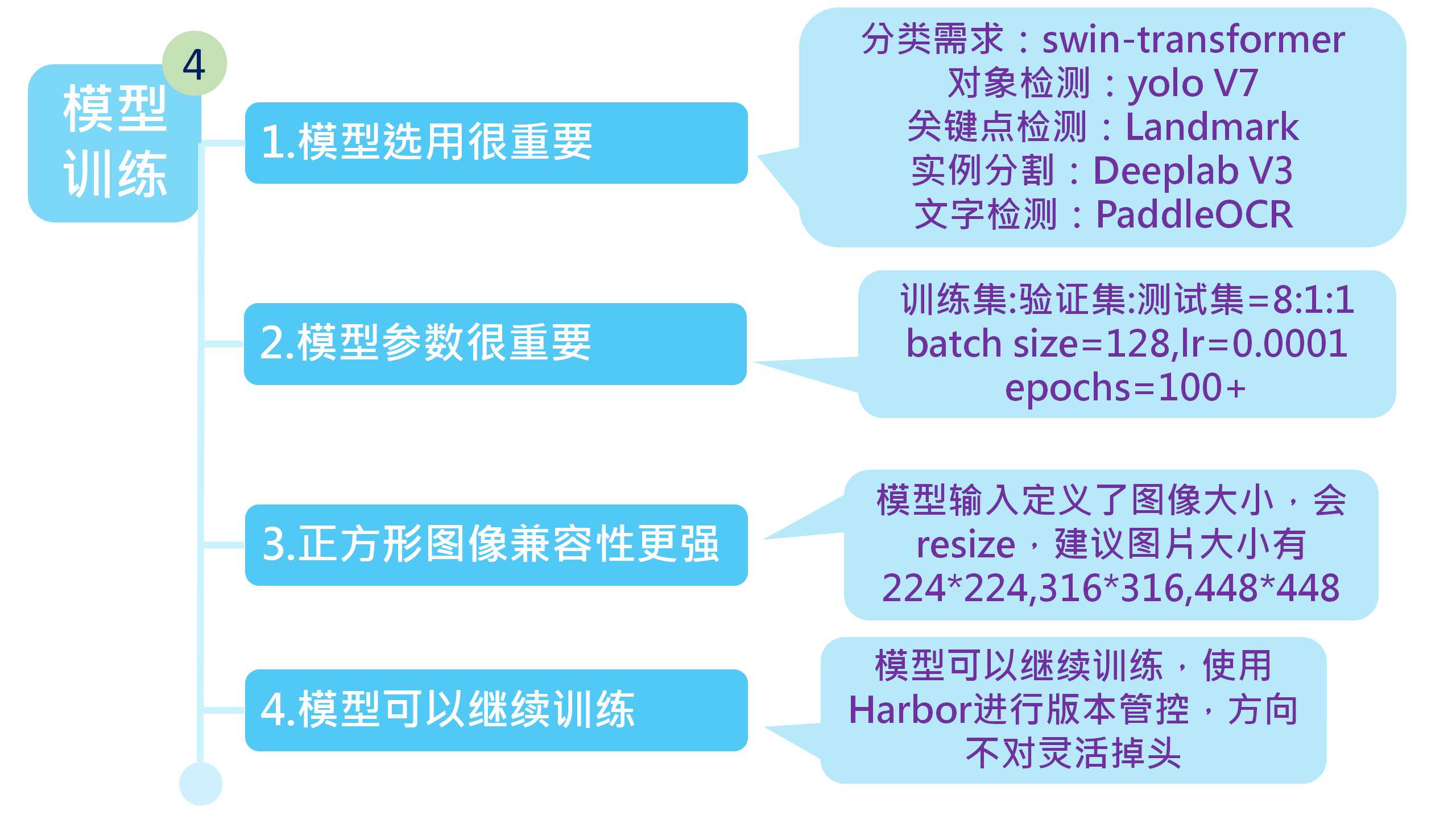
步骤4:模型训练
模型训练是深度学习工程师很重要的技能,目前的市场早已经不是一家吃天下,所以在2017年深度学习大爆发时候,出现了很多深度学习框架和模型,模型的选择和相关超参数调试就变成了很重要的技能。
1.模型选用很重要,根据我们的经验,当前(2023年)分类选用swin-transformer模型,对象检测选用yolo V7,关键点检测选用Landmark,实例分割选用Deeplab V3,文字检测选用PaddleOCR,其他未提到的均可以尝试用swin-transformer找找看修改版,因为swin-transformer本身就是基于擅长NLP的transformer改进的。
2.模型参数很重要,在训练模型之前,我们建议的原始数据分布是训练集:验证集:测试集=8:1:1,总数量越大,训练集所占的比例应当越大,我们还需要决定我们的超参数是否符合我们的需求,比如batch size,如果我们的GPU 显存大于8GB,那么我们可以将其设置成128,这样做的目的是加快速度,与之相关的还有lr学习率,为了保险起见,我们的这个数值一般设为0.0001,那么epochs就要设置成大于100,因为学习率很低的时候,训练圈数必须足够才能让模型收敛。
3.图像一般是正方形,修改也尽量遵循这个原则,在深度学习中,一般为了兼容性质,会将图片转换成正方形,即使输入的图不是正方形也会通过resize的方式强制转换成模型的输入大小,目前大部分采用224*224,316*316,448*448作为模型输入图片大小,所以我们尽量将我们的目标检测区域定义成正方形,差异太大会因为resize丢失关键信息。
4.模型可以继续训练,在我们做项目的时候,一个方向评估行不通后一般不会全盘推倒重新开始,为了节省时间我们会基于之前某个最优版本继续训练,为了方便版本管控,我们一般在发布后使用Harbor进行版本管控。
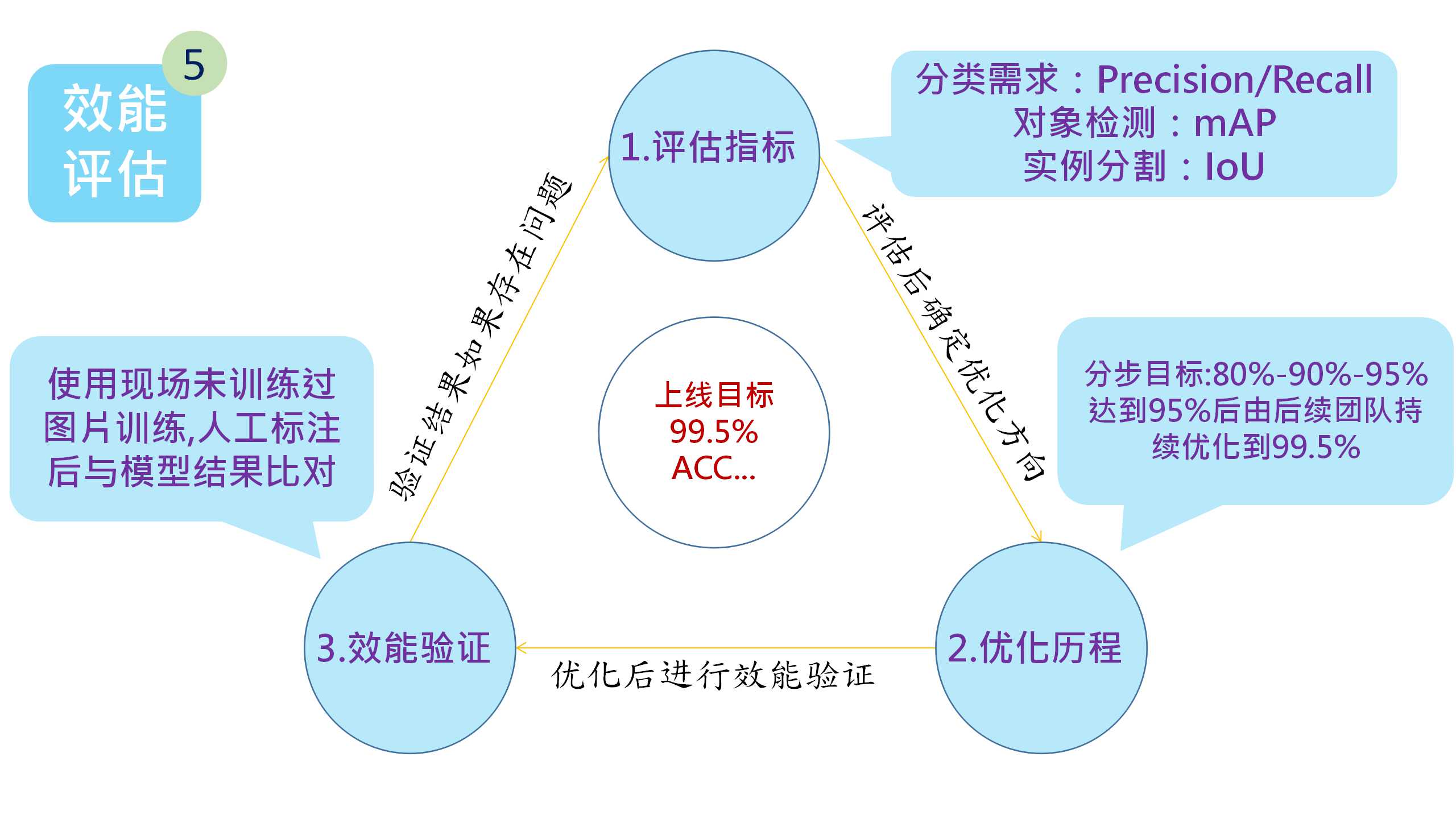
步骤5:效能评估
效能评估是决定模型是否可以在正式环境使用的衡量标准,我们在使用的时候一定要客观公正的去面对效能评估不达标的问题并找到根本原因去改善,不然真正上线后可能会惨不忍睹并且因为现场环境的复杂性不好找原因。
1.评估指标的选用很重要,模型分为很多种,评估指标选用是否合适就显得特别重要,分类模型建议使用混淆矩阵(confusion matrix)和Precision/Recall方式进行评估,值得注意的是要留意模型关注点,模型需要检查出NG的对象,那我们应当把NG设置成正向的和主要的,对象检测模型建议使用mAP,也就是平均AP值作为评估指标,实例分割建议IoU(Intersection over Union)作为评估指标,也就是“预测的边框” 和 “真实的边框” 的交集和并集的比值。
2.评估指标优化历程,在项目一开始就将目标定得很高是一种很愚蠢的做法,因为一开始的高目标将让团队所有人都望而不及,团队一开始的信心就会被夭折,正确的做法我们推荐将指标设置成3个阶段,比如80%-90%-95%,可能95%也不能满足我们的最终目标,但是我们也不妨先将目标定为这个数值,因为95%不会像最终目标的99.5%那样遥不可及,还有一个点就是目标越向上是越难以达成的,95%的下一个目标应当是97.5%而不是直接设置成99.5%,95%到99.5%需要的往往是时间积累的细节所影响的,可以将这个任务交给项目的维护团队,周期可以设稍微长一点,比如说6个月,这样也是为了让这个项目能够向着下一步的MLOps发展。
3.效能评估的验证很重要,我们可能会遇到一个问题就是模型跑出来的结果很理想,达到了预期目标99.5%,但是只要一进行验证集验证就瞬间到80%以下,这种现象我们称之为“过拟合”,也就是模型太过依赖原始训练集,导致验证失效,解决的方法是进行效能评估时使用新的数据(不能使用原始数据集),真实值的获取要让人工进行判定,再与模型判定结果结合得出其效能值,优化效能的记录我们也建议做成趋势图,趋势图的好处是在模型效能降低时能第一时间回溯到最佳模型继续训练。
步骤6:上线运行
上线并不代表着项目的结束,而是代表着项目进入下一个阶段的验证,以最真实的现场环境来验证大家项目期间的成果遵循的是实践第一原则,上线运行前期可能需要有人工的辅助纠错,我们需将这些点记录下来使用程序进行完善,然后需要考虑项目的平行展开。
1.运行状态记录,我们称之为存log,存log的意图不仅仅是出现问题后的备查,也是为了未来的MLOps(深度学习的持续集成,交付和部署)做准备,而误差分析,模型运作解释,可视化工具离不开log。注意这里的log不是传统的文字log,而是项目的对象,项目检查图片给出类别,我们的log关键就是图片+类别(可能会是以类别命名的图片,再加上日期),如果是音频给出文字,那么我们的log就是音频+文字(以文字+日期命名的音频记录)。
2.运行问题解决,我们上线实际环境运行后会遇到很多问题,遇到问题我们不要慌张和气馁,仔细将问题的真因找到并记录下来(记录这一步很重要,属于经验共享传承,加快后续开发),当遇到大方向的问题时一定要尽快切换跑道,我所在的团队曾经做过一个排线4周定位点的项目,当时采用DeepLab模型,但是模型经常有丢点,当时想了很多方法去解决这个丢点的问题,比如设置默认的点位置为(0,0),只有在有推论结果时再赋值,然后又遇到结果精度的问题,我们需要得到这个排线的中心点坐标,四点就是用来定位确定位置的,当两个点都是(0,0)坐标的时候,根本无法给出正确的位置,这个问题优化三周无解。后来我们直接换成了simplepose模型才根本解决了这个问题,但是因为中途耽误的时间,最终两个并行的项目决定舍弃这个排线定位项目,算是项目夭折。
后记
目前的深度学习已经在向着MLOps方向发展,出现了自动打包标注方法,也出现了对抗网络(GAN,模型在训练时还会生成一个对抗模型,两个模型之间相互角力将参数优化到最优),我们目前还处在弱人工智能阶段,人工智能只能帮助人们实现一些重复性高,目标明确的任务,但是不具备自我思考进化的能力,未来的发展方向也许是人工智能的自我进化,需要跟上脚步。