
Swin-transformer深度学习模型是2021年由微软亚洲研究院提出的一种基于Transformer的深度学习网络结构,目前在图像分类、目标检测、实例分割和语义分割竞赛中保持最领先地位,我们来了解下Swin-transformer到底有什么过人之处:
首先需要了解一些基础知识
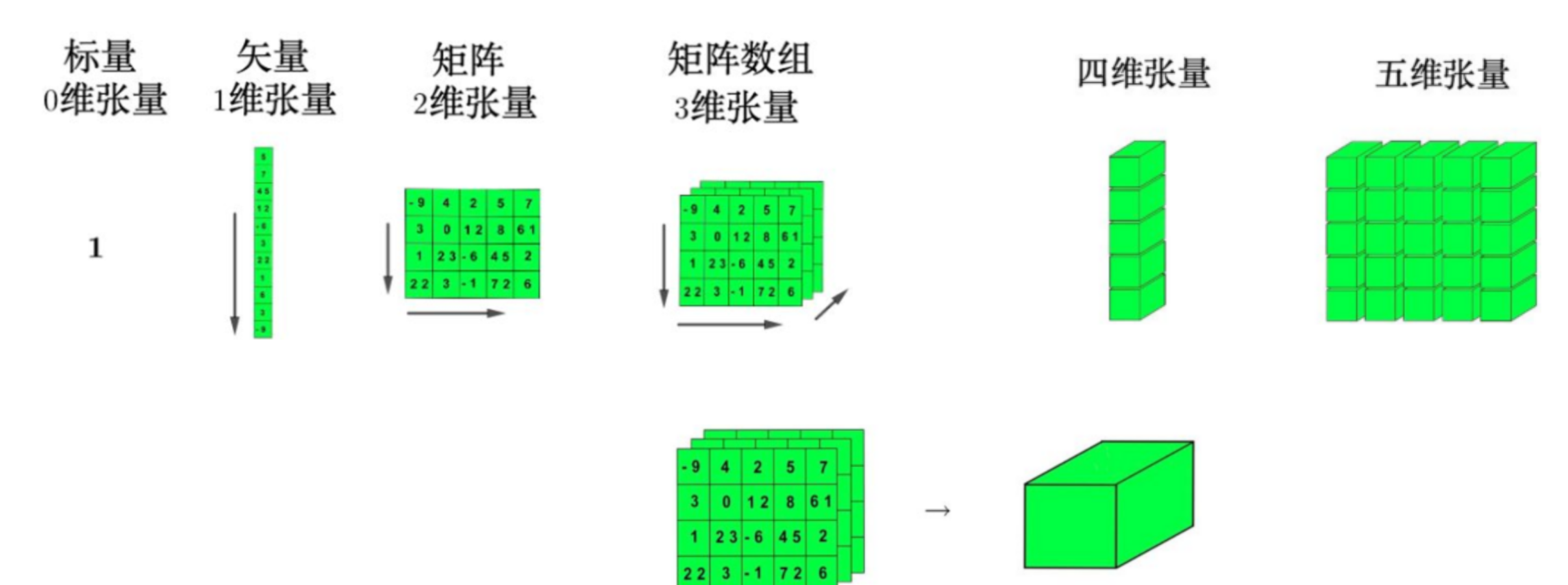
张量(Tensor)
张量是多维数组,是某种几何对象,不会随着坐标系的改变而改变,是矢量和余矢量(covector)通过张量积(tensor product)组合而成,有多重线性映射关系的量,可以说,张量的发现是深度学习的发展根本,如果没有多维度的数据,我们将见不到Swin-transformer。
卷积(Convolution)
卷积可以说成翻卷积分,其实本质上是一个积分变换的数学方法,在离散上对应着卷积和,卷积跟傅里叶变化有着密切的关系,几乎所有的信号系统,都离不开卷积
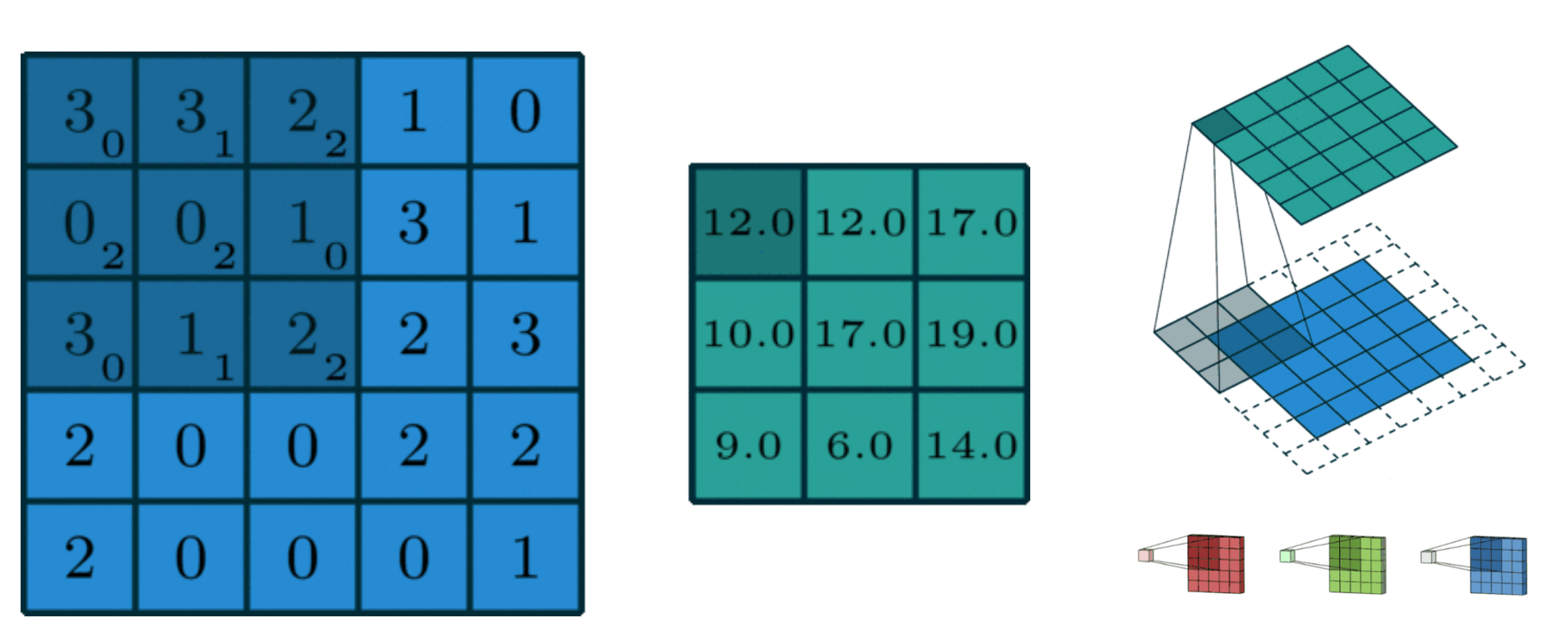
卷积神经网络(CNN)
卷积神经网络(CNN),是一类包含卷积计算且具有深度结构前馈神经网络,是深度学习(deep learning)的基础算法之一

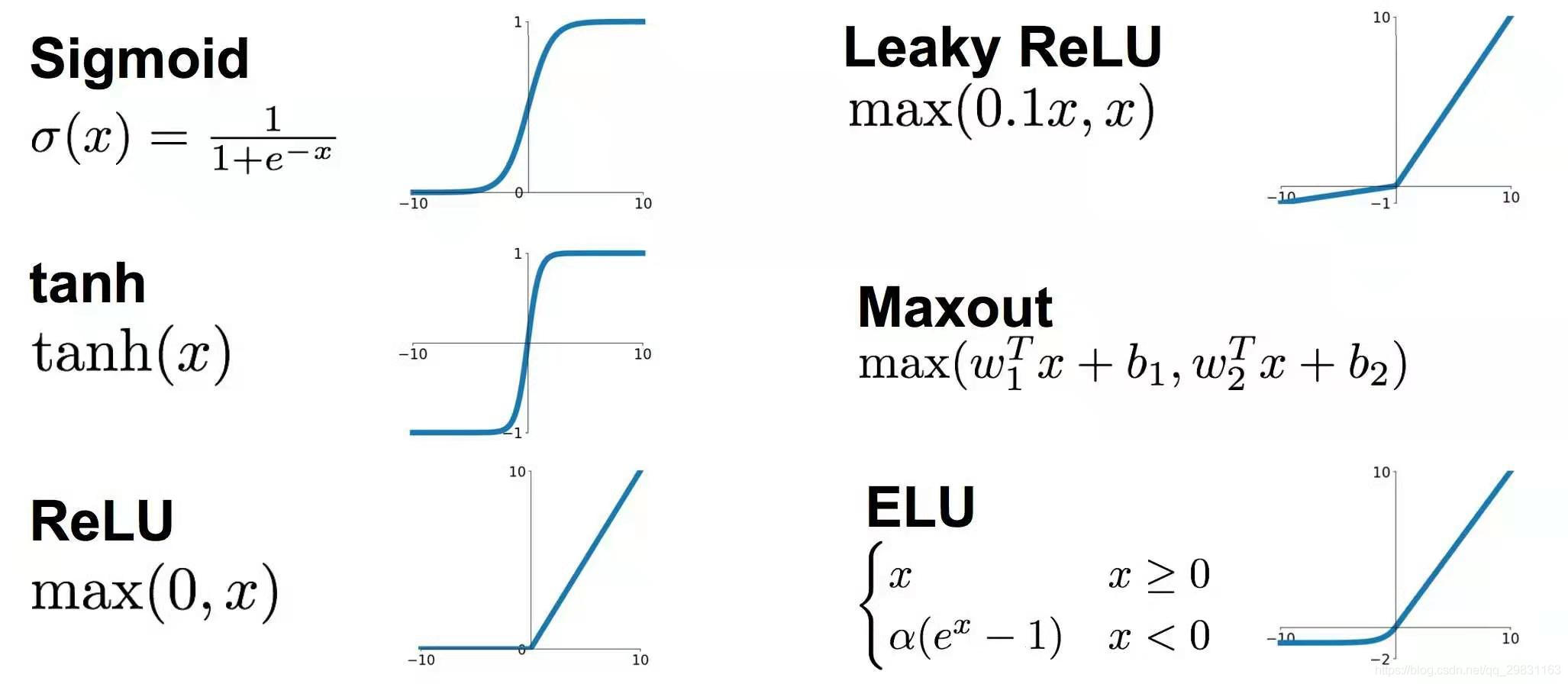
激活函数
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。
Swin-transformer深度学习模型
Swin Transformer是2021年由微软亚洲研究院提出的一种基于Transformer的深度学习网络结构,在图像分类、目标检测、实例分割和语义分割竞赛中保持最领先地位.(目前在kaggle榜单屠榜,所有的比赛前10名几乎都是使用Swin Transformer模型)
什麽是transformer?
Transformer是谷歌大脑在 2017 年底发表的论文 attention is all you need 中所提出的 seq2seq (序列对序列)模型,主要用于NLP
Transformer 使用了位置嵌入 (Positional Encoding) 来理解语言的顺序,自注意力机制(Self Attention Mechanism)和全连接层进行计算
Swin-transformer使用了哪些技术?
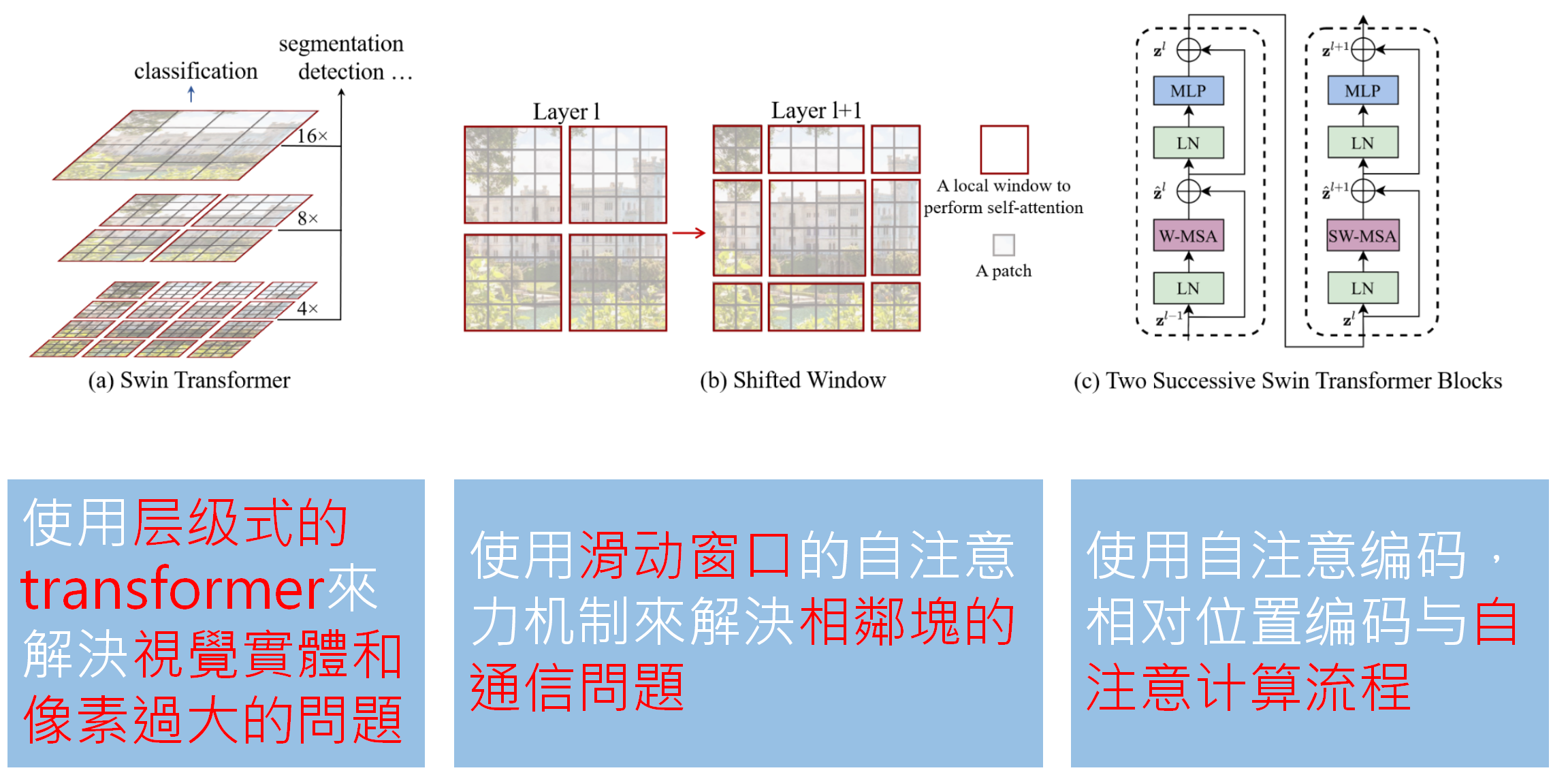
使用层级式的transformer来解决视觉实体和像素过大的问题
使用滑动窗口的自注意力机制来解决相邻块的通信问题
使用自注意编码,相对位置编码与自注意计算流程
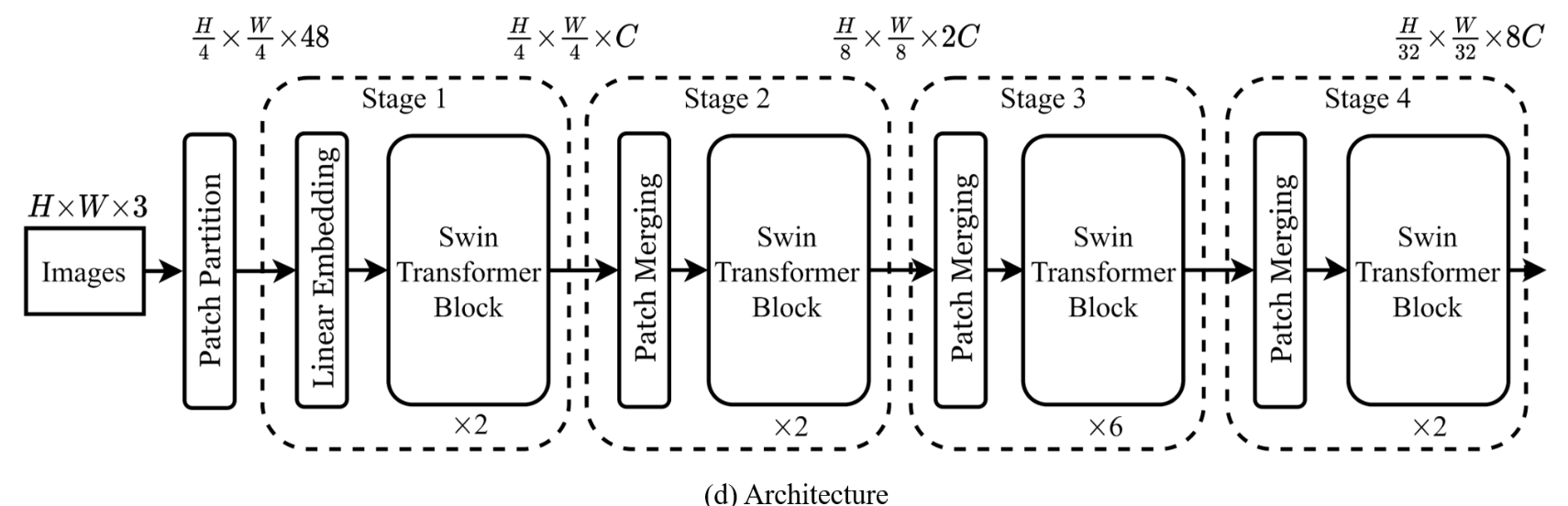
Swin-transformer结构解析
假设我们有一张224*224*3的彩色图像需要进行训练和推论,那么在Swin-transformer结构中,这张图会进行如下的变换:
原始图像:224*224*3
经过patch parition时每四个p为一个patch,此时图像为:56*56*48
stage1时,我们把图像维度定义为常数C,于是进入时图像为56*56*C,然后经过transformer的拉伸,变成了3136*C,但是3136的长度对于一般处理文字的transformer来说太长了(文字一般在100字以内),所以使用了层级式的transformer来进行处理,就又是转换成了56*56*C,只是这里的56是分成了56个层级,而不是二维的意思。
stage2时,模型将相邻的四个patch(2*2)合并,然后使用1*1的卷积核来降低通道数,图像变化是56*56*C变成28*28*4C,然后卷积变成了28*28*2C。
stage3时,依旧将相邻的四个patch(2*2)合并,然后使用1*1的卷积核来降低通道数,图像变化是28*28*2C变成14*14*8C,然后卷积变成了14*14*4C。
stage4时,再依旧将相邻的四个patch(2*2)合并,然后使用1*1的卷积核来降低通道数,图像变化是14*14*4C变成7*7*16C,然后卷积变成了7*7*8C。
于是,我们的224*224*3的图像就被转换成了包含特征的7*7*8C,这样的图像在计算机看来很好辨认是否符合我们的要求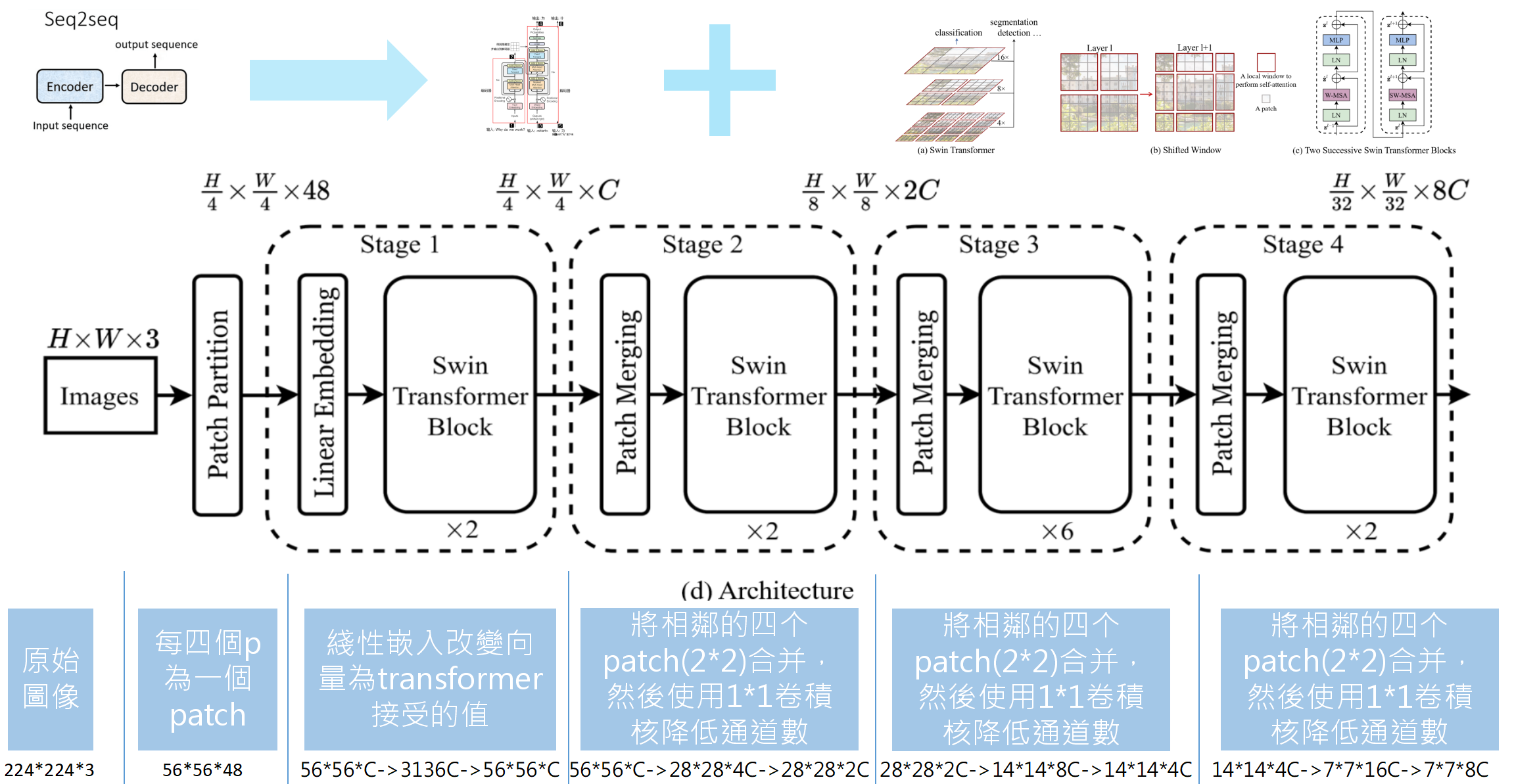
后记:
也许有小伙伴早就发现了问题点了,为什么他们会将相邻的四个patch(2*2)合并?
官方其实有解释这个问题,大概意思就是实验出来发现四个合成一个效果最佳
还有另外一个问题,为什么需要用1*1的卷积来降低维度?不降低不行么?
官方没有正面解释这个说法,大概还是实践得出降低维度可以减少计算量且不损失性能
参考: