
Python的数据类型的配置是python如此简洁易用的原因之一,其数据类型共有8种,分别是Number(数值)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)、Boolean(布尔值)、None(空值),这些数据类型均可以通过赋值号"="来进行赋值。
Python变量
在说明python数据类型之前需要有一个容器来承载这些变量,我们通过赋值号"="来把某个数据赋值给一个变量,其本质是一个标签,而这个数据就可以是上方的八种类型,需要注意的是python变量可以随意命名,但是需要遵循一个原则:
Python变量由数字,字母,下划线组成,数字不能作为开头,区分大小写
如下是一些赋值的范例
a=1 #将数字赋值给a
b="111" #将字符串赋值给b
c=["11","1"] #将列表赋值给c
d=("11","1") #将元组赋值给d
e={"11","1"} #将集合赋值给e
f={"date1":"1","date2":"2"} #将字典赋值给f
g=True #将布尔值赋值给g
h=None #将空 赋值给h我们也可以在同一行对多个变量进行赋值,用逗号隔开,其效果和单独写完全一样
a,b,c,d,e,f,g,h=1,"111",["11","1"],("11","1"),{"11","1"},{"date1":"1","date2":"2"},True,None值得注意的是赋值号会为变量分配一个容器,如果赋值的量也是一个变量且其发生变化,那么这个变量也会跟随变化(注意只要在其作用域都会变化,包括函数内部的赋值,当前变量被重新赋值的时候,生效的依旧是该变量前次的赋值,此时也就不会再变化),如下例子
a=[]
b=a
#a=["RE"] #这里的a若被再次赋值,b的值依旧为前一次的a(空列表)且不会再发生变化
a. append(1) #这里的a一开始是空的,b生成的时候指向的其实是a这个变量,所以当a添加1过后,b也会更新成添加了1的a变量后面有时候会出现逗号,如"a,",这样的变量表示tuple(元组)的类别转换,当tuple中只有一个元素的时候,变量加上都好会将元组转换为文字或数字
a = (1,) #出现特定格式的元组,里面只有一个元素且跟了逗号才能生效
c1 = a #c1是一个元组
c2, = a #c2输出将是一个数字Python的函数内部都是一个独立的空间,不能相互使用,在变量作用域中,python有如下定义:
1.Python 主要程序定义「全局」的名称空间,在主程序定义的变量是「全局变量」
2.每个函式里定义的变量就是「区域变量」
3.每个名称空间里的变量名称都是「唯一的」
4.不同名称空间内的变量名称可以相同,例如函式 A 可以定义 a 变量,函式 B 也可以定义 a 变量,两个 a 变量是完全不同的变量
值得注意的是python对变量的解析顺序,会从最内层 ( 区域命名空间 ) 开始往外层搜寻,直到找到对应的名称为止 ( 如果找不到就会报错 ),简单记忆为:由内向外,找到即止
我们可以使用global来定义全局变量,具体语法如下:
global 变量名称
我们也可以使用globals()和locals()函数来回传目前域变量的方法,括号内无参数
Python Number(数值)
Number就是阿拉伯数字,在python里数字包含整数,浮点数(有小数点),底数,我们可以通过type(数据)来判断数据的类型
整数可以通过int(数据,进制)来进行转换,数据可以是小数,字符串和布尔型数据,如下为范例:
print(int(3.678)) # 3 强制转换会直接舍弃小数部分
print(int(True)) # 1 布尔型只会被转换成0或1
print(int('101', 2)) # 5 二进制字符串
print(int('101', 8)) # 65 八进制字符串
print(int('101', 16)) # 257 十六进制字符串使用浮点数和整数或者布尔值进行运算,结果均会是浮点数,浮点数的转换用float(数据)来进行,由于计算机的位元限制,有小数点的数字最多只有15位有效数字
而底数则是在数字前方加上0b(0B),0o(0O),0x(0X)的底数来表示二进制,八进制和十六进制的数字,在位元级模式下,往往使用二进制,八进制和十六进制。
在python中的布尔型(bool)数据也可以作为数字使用,通常True表示1,Fasle表示0,可以通过函数bool()将任何数据转换成布尔型数据(非0的值均会被转换成True),主要用在逻辑判断中。
Python字符串
字符串是python最常见的序列,其被放在单引号'*'或者双引号"*"之中,在python中单引号和双引号的作用完全一样,但需要配对使用,如果字符串有换行,则需要使用三引号'''*'''或"""*"""将其包裹。若需要将其他数据转换成字符串,则使用str()来进行转换
值得注意的是在python中的反斜杠\表示转义字符,常用转义符如下: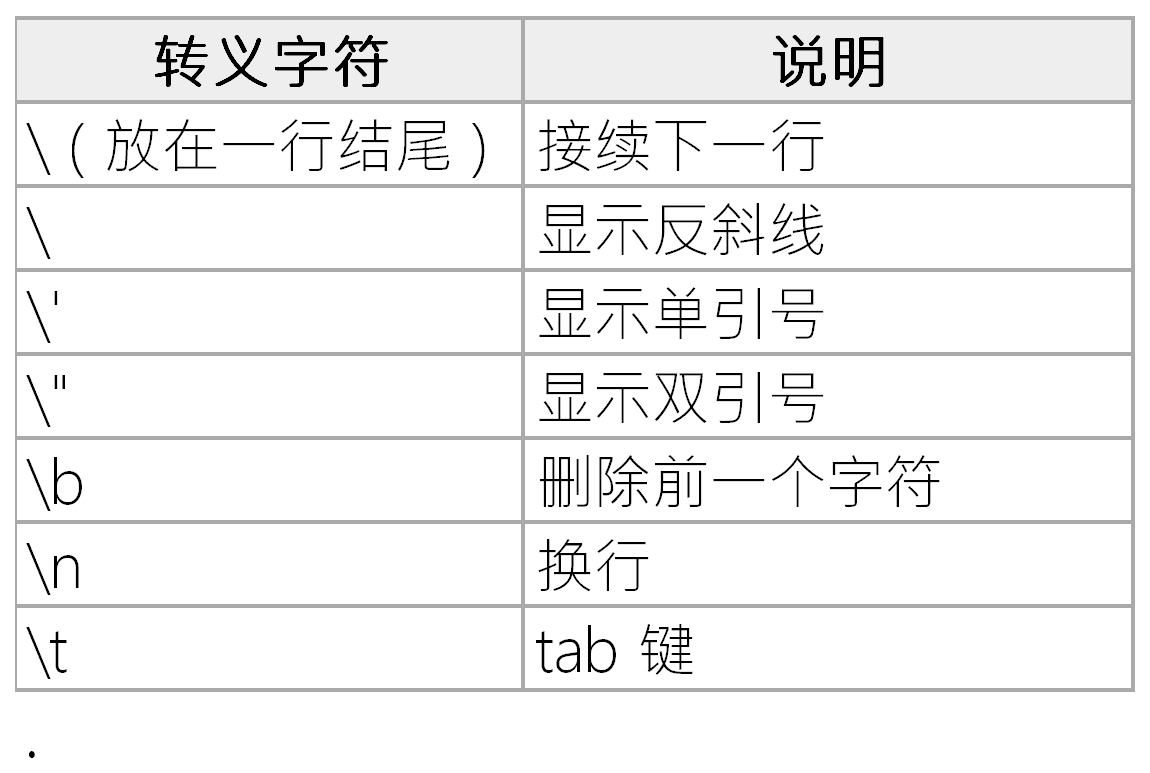
当我门需要将多个字符串拼接的时候,使用+号可以将字符串或变量进行拼接,还有一种"字符串后方放置"只能针对字符串拼接,如a='111''222''333'是可以将三个字符串拼接后赋值给a的。
我们需要多个相同字符串的时候,可以使用*号来说明倍数,如a="PASS"*10表示把10个PASS字符串拼接后赋值给a
如果我们需要截取字符串中某个位置的字符串,可以使用[]符号来表示取的位置,如a[0]表示取第一个字符串(在python中下标以0开始表示第一个,-1则表示最后一个,若需要一段类容,可以通过[ start:end:step ]来表示区间,表示从start开始到end前一个字符结束,步进为step,以此类推)。
如下操作中的str表示需要操作的字符串
若要计算字符串的长度,可以用len(str)函数,将返回目标字符串(不包含转义字符)的长度
要按照指定的分割符号拆分字符串,可以使用split()函数,其格式为str.split('分割字符'),会生成一个数组。
要替换字符串的某些字符,可以使用replace()来进行简单的字符替换,其格式为str.replace(旧的字符,新的字符,替换数量)来进行操作
要去除字符串开头或结尾的某些字符,可以使用strip()来进行操作,其格式为str.strip(剔除字符),不填写需剔除字符则默认为空格,与其对应的是str.lstrip(剔除字符)表示只剔除左边,而str.rstrip(剔除字符)表示只剔除右边。
要搜索字符串中的某个字符,可以使用find()或index()两种方式,其格式为str.find(字符)和str.index(字符),返回找到字符第一次出现的位置,默认从左边开始寻找;对应的rfind()和rindex()则会从右边开始寻找,如果没有找到,find()则返回-1,index()会报错。
Python字符串的常用方法整理如下
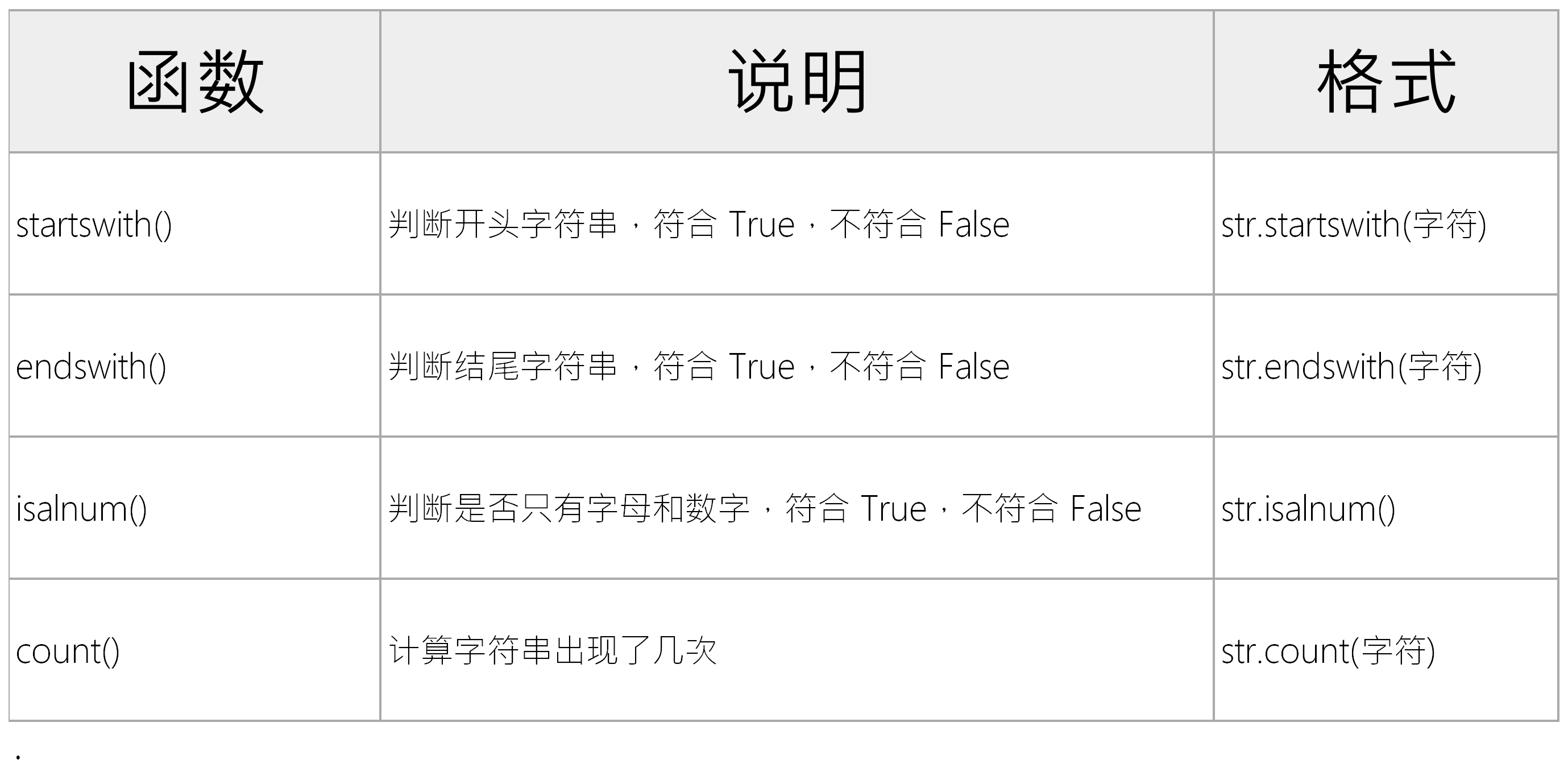
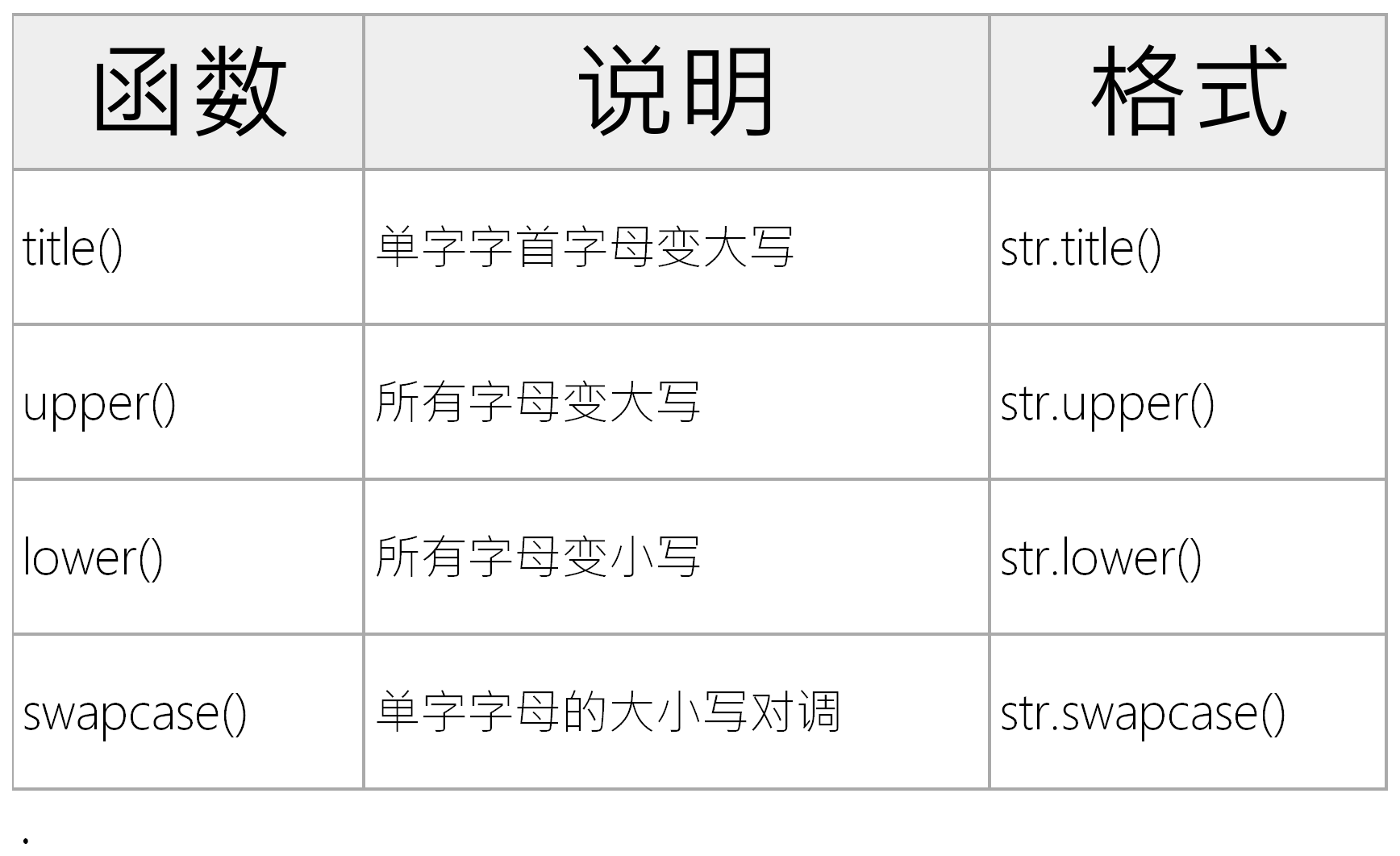
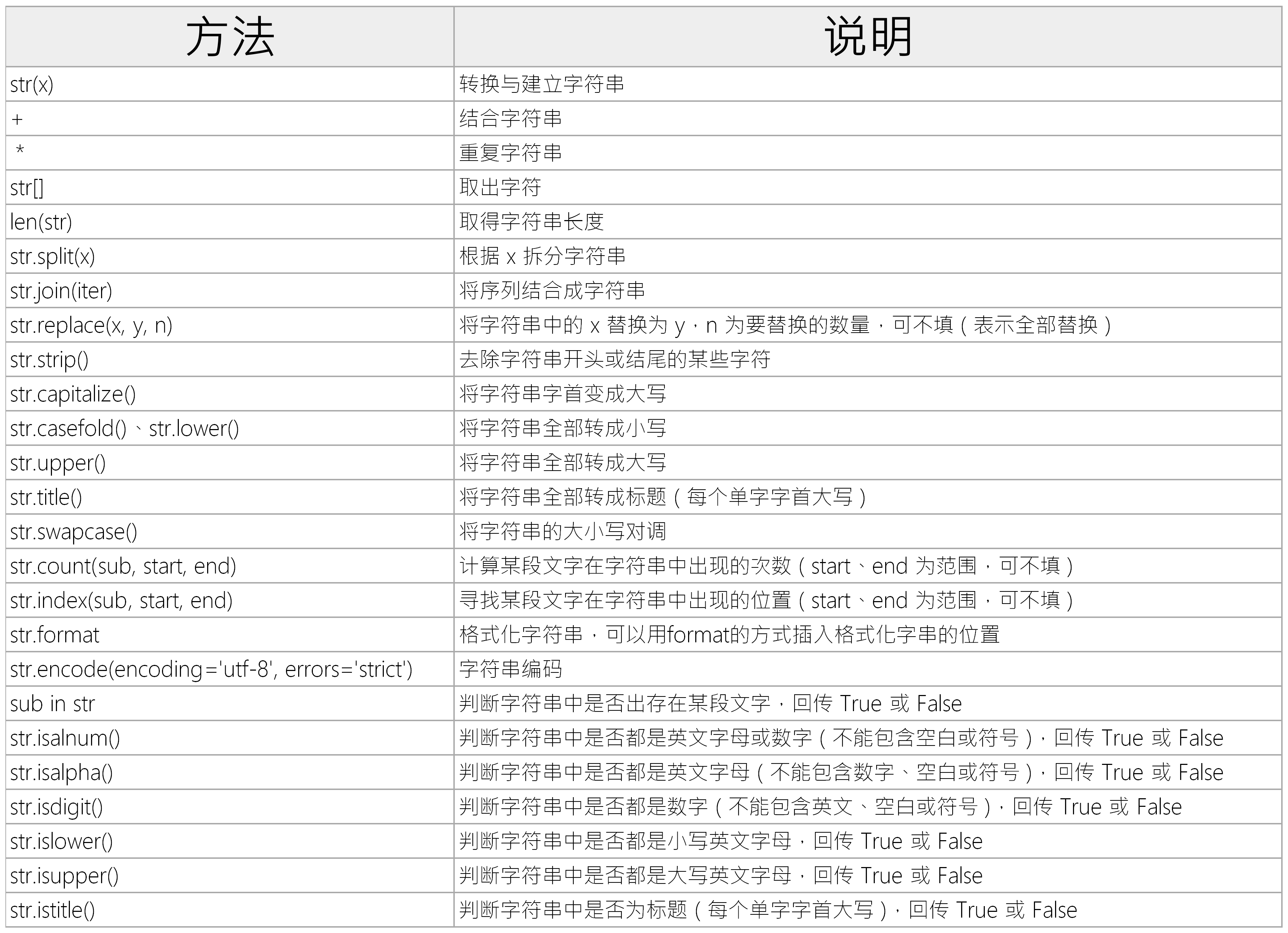
Python文字与格式化
在python中我们除了使用基本的字符串拼接基本的字符串,也可以针对不同的格式将资料插入到字符串中,在使用过程中反而是这种插入方法更加灵活好用。
在使用上我们可以通过位置对应进行插入,其基本格式为'%s'%'a',这个语句的作用可以将后面的'a'以%s的格式插入前面的字符串里面,如下是格式化字符串的定义
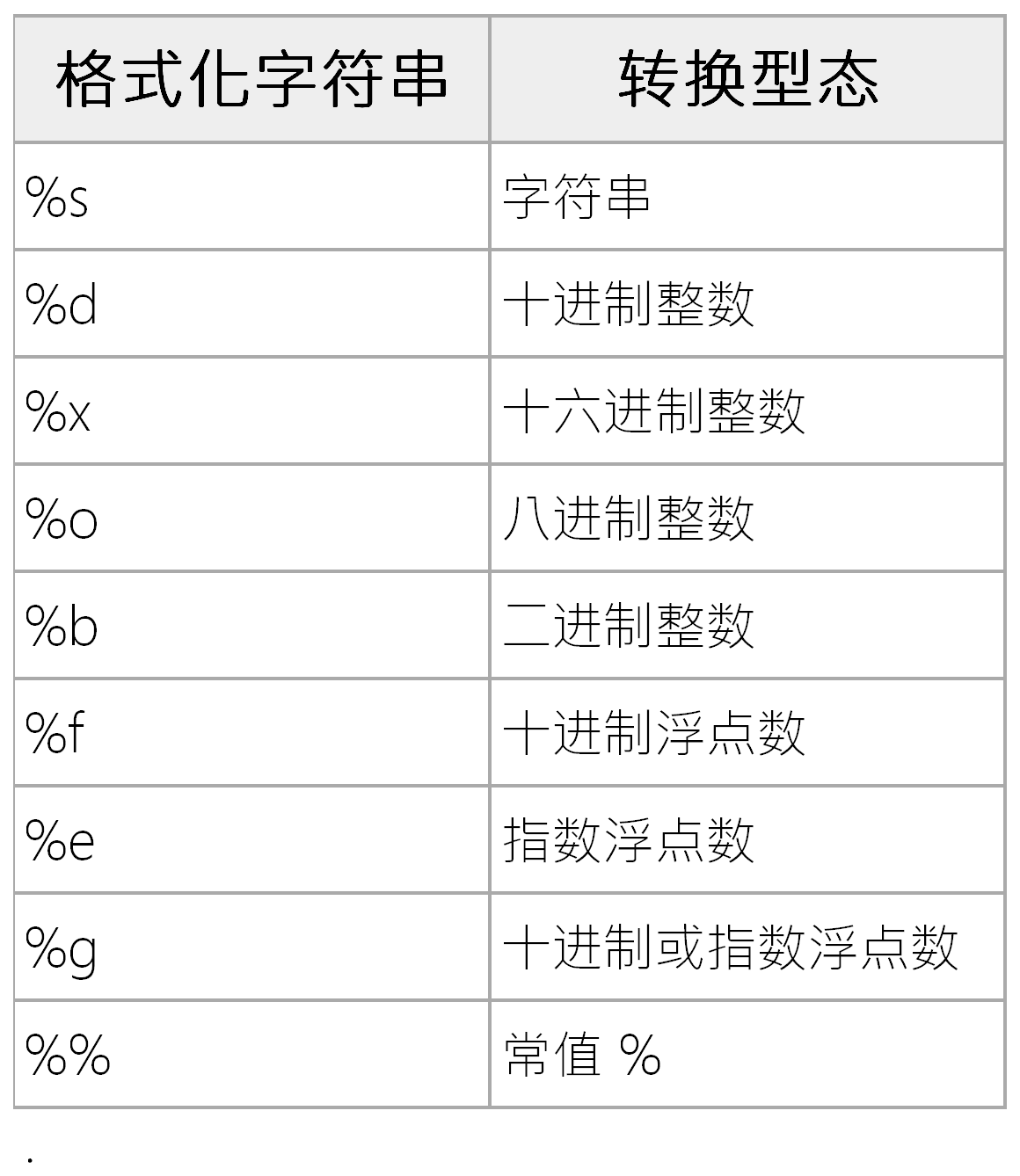
我们也可以在%后面加上数值来指定最小宽度、最大字符、对齐与精确度,参考如下表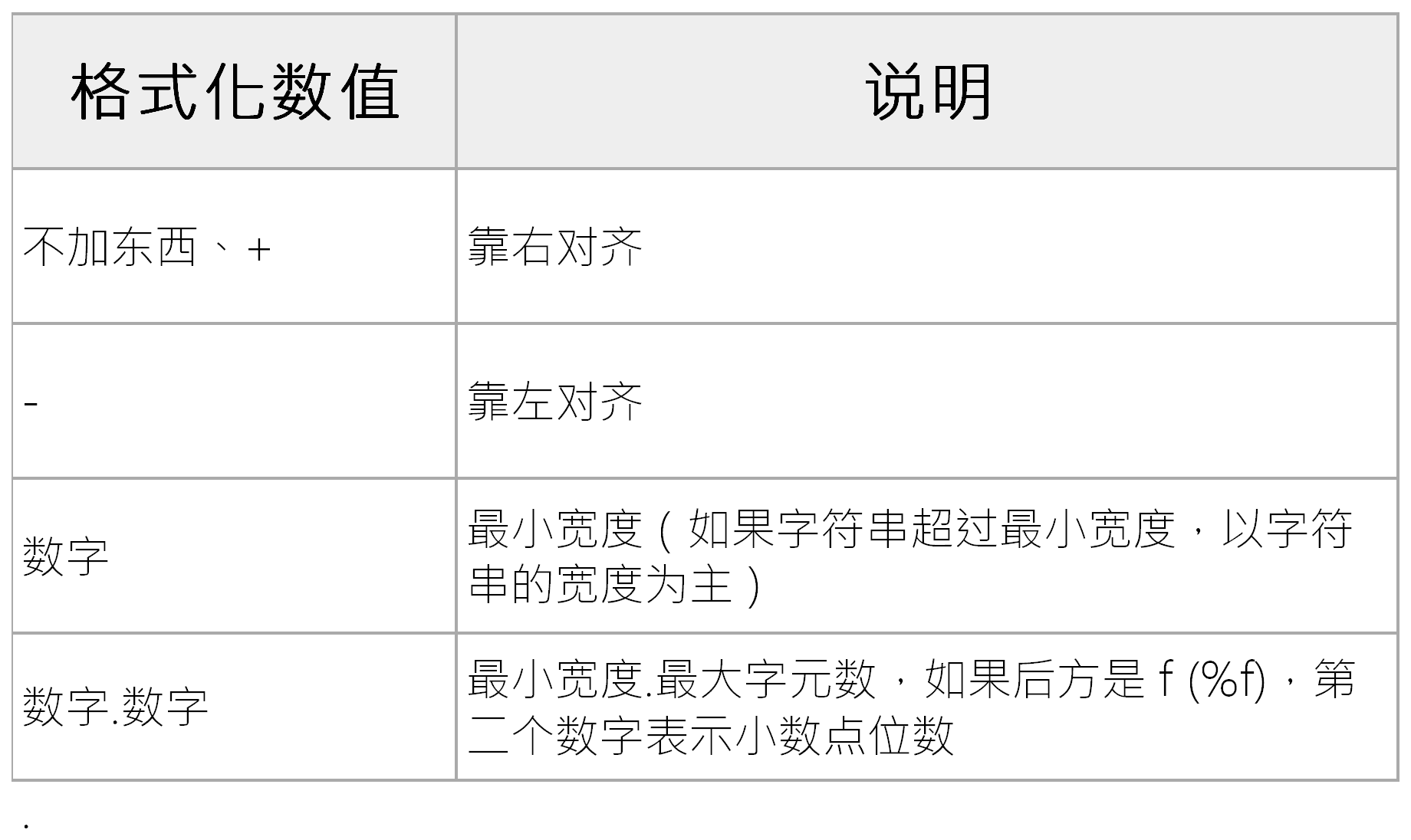
当有多个类容需要格式化时,可以用小括号括起来并用逗号隔开调用,比如下方的代码:
print("%s %s"%('hello','word')) #以%s格式依次插入字符串'hello'和'word'
Python3还新增了一种格式化的方式,在字符串str内使用{}号,然后使用str.format()来进行插入,和前面的插入方式一样是按顺序插入,也可以在{}中写入数字表示插入第几个数据,下标以0 开始,如下范例
print("{0} {1}".format('hello','word')) #使用{}来表示插入位置,使用format来插入
#也可以在{}中填入名称来进行插入
print("{a} {b}".format(a='hello',b='word')) #通过名称来插入数据
#还可以在{}填入字典的索引来进行插入
dic={'a':'aaa','b':'bbb'}
print("{0[a]} {0[b]}".format(dic)) #将字典dic的内容通过索引插入了前面的{}中新版的格式化字符串和%定义有差异,可以加入其他数值来指定最小宽度,最大字符和对其精确度
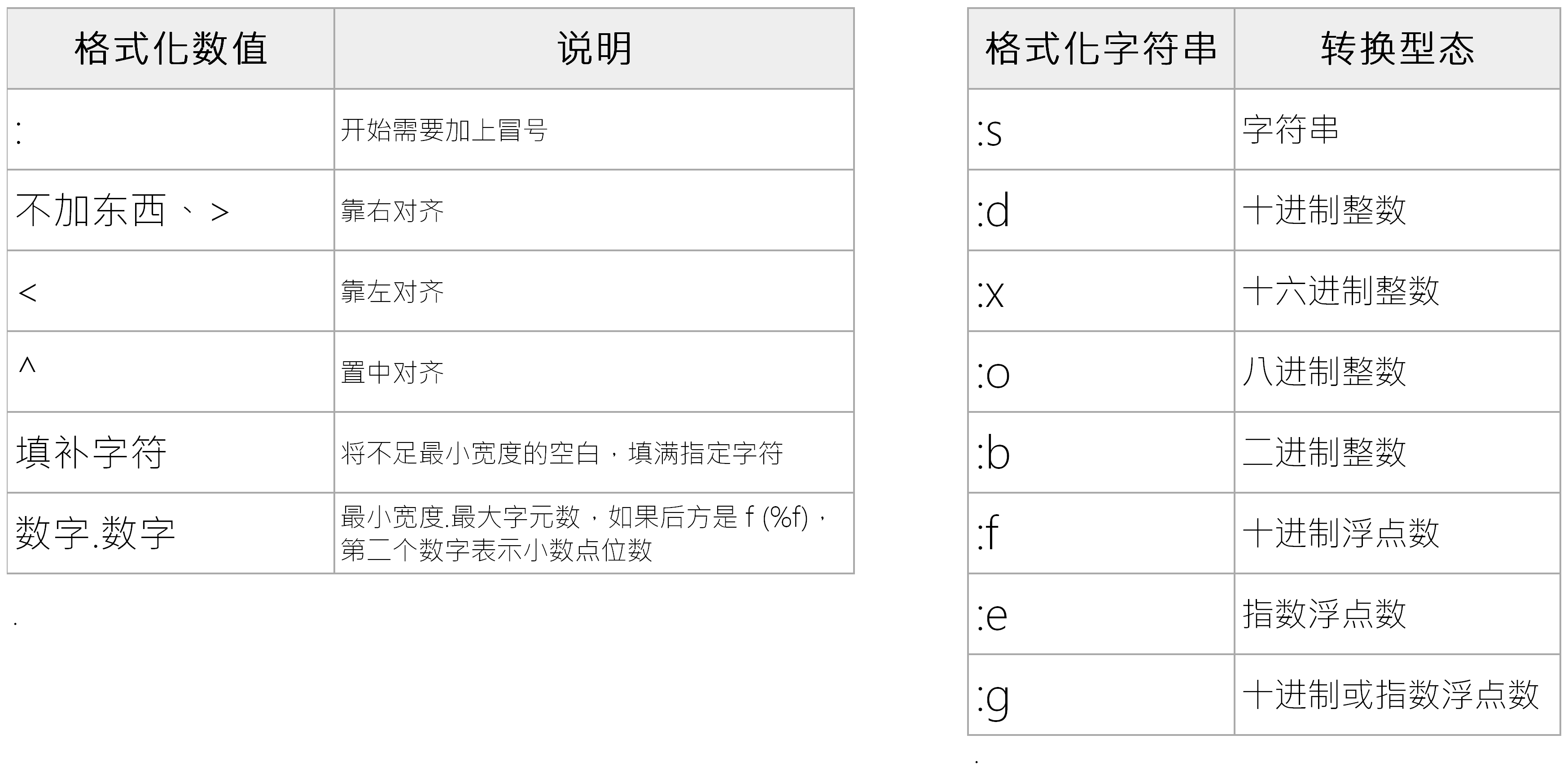
资料的状态由%改变成冒号":"表示,下面的例子可以看到 {:-^10s} 会将 world 置中对齐,并将不足最小宽度的部分补上 - 的符号,{:^10.3f} 会让 123.456789 只留下小数点三位
a = 'hello {}, I am {}'.format('world','ric')
b = 'hello {:10s}, I am {:10s}'.format('world','ric')
c = 'hello {:>10s}, I am {:>10s}'.format('world','ric')
d = 'hello {:-^10.3s}, I am {:^10.3f}'.format('world',123.456789)
print(a) # hello world, I am ric
print(b) # hello world , I am ric
print(c) # hello world, I am ric
print(d) # hello ---wor----, I am 123.457
python3.6加入了一种新的格式化功能,f-string方法,其格式为f{变量或表达式},开头可以使用f或F,结果会将内容插入到指定的位置,下方的程序执行后,会将a和b放入到字符串中
a = 'world'
b = 'ric'
print(f'hello {a}, I am {b}')使用f-string方法也可以加入数值来指定最小宽度,最大字符,对其精度,其用法和.format类似,了解原理后,我们就可以实现 补零 效果,如下代码段
for i in range(1,101):
print(f'{i:03d}',end=' , ')Python列表(list)
Python中的列表(list)是很常见的数据格式,列表的元素可以是任何一种物件,我们看到的图片甚至电影都可以转换成多维列表来表示,列表在python中的使用频率甚至比str还要高
在建立list的时候,我们有三种方法
1. 中括号[]直接定义
2. 使用list()函数进行转换
3. 使用split()函数拆分字符串生成
a=["123"] #使用中括号直接定义了一个list,可以定义空列表
a=list(("123","456"))#使用list()函数将字符串转换成了list,注意这里的内层括号表示一个整体
a="123,456".split(",")#使用split()以逗号为分割符拆分了字符串我们可以用加号+或者extend()来拼接多个列表,如下范例
a=["123","456"]+["789"] #使用+号拼接了两个list
b=a.extend(["789"]) #使用extend()函数将"789"拼接到前字符串末尾,注意extend()并不会回传新list,被改变的是原list,这里被改变的是a读取list的方法有两个,一个是offset方式(即下标方式),另一个是slice()函数(即使用冒号:来说明取值范围和步进的方法),我们通过下面的范例来理解
a=["1","2","3","4","5"]
print(a[0]) #使用offset方式读取liest类容,从0开始,也可以为负来表示反方向取值,二维list可以使用两对中括号来取值,如a[0][0]表示a里面第一个的第一个元素
print(a[0:3]) #使用slice()来取第0-2号元素,右边的3下标不会被取到,简记为“左闭右开”取值方法,a[X:Y:Z]中表示从X开始取到Y-1元素,每Z个取一个(步进),所以可以用a[::-1]来反转整个list修改list的方法只是在读取的方法上进行赋值即可,也是offset方式(即下标方式)和slice()函数(即使用冒号:来说明取值范围和步进的方法)来进行,如下范例
a=["1","2","3","4","5"]
a[0]="2" #使用下标表示元素并赋值
a[1:4]=["3","4","5"] #使用冒号表示范围并赋值,赋值的数量可以多可以少,但是会完全替换掉指示的范围内的元素
python也提供了两种列表添加新元素的方法,即append()和insert(),其中append()会将项目作为元素添加在list最后面,而insert()则可以添加在任意位置,如下是范例
a=["1","2","3","4","5"]
a.append("6") #在a的末尾添加"6",也可以添加任何python对象
a.insert(3,"6") #在a的3下标(第四个)位置插入"6",若指示为负,则会插入第负数-1个位置要删除列表中的元素,有四种方法,分别是del,remove(),pop()和clear(),del用来删除已经知道位置或范围的,remove()则会根据类容删除第一个元素,pop()是取出并移除元素并会返回取出的元素,clear()则是清空整个list,使其没有元素,范例如下
a=["1","2","3","4","5"]
del a[0] #使用del删除了a的第一个元素
a.remove('2') #使用remove()删除了a里面的第一个"2"元素
b=a.pop(2) #使用pop()取出了a的第三个元素并赋值给了b,并移除了第三个元素
a.clear() #使用clear()清空了整个a列表,此时a为空列表如下有一些常见的列表操作方法,可以加快我们的程序开发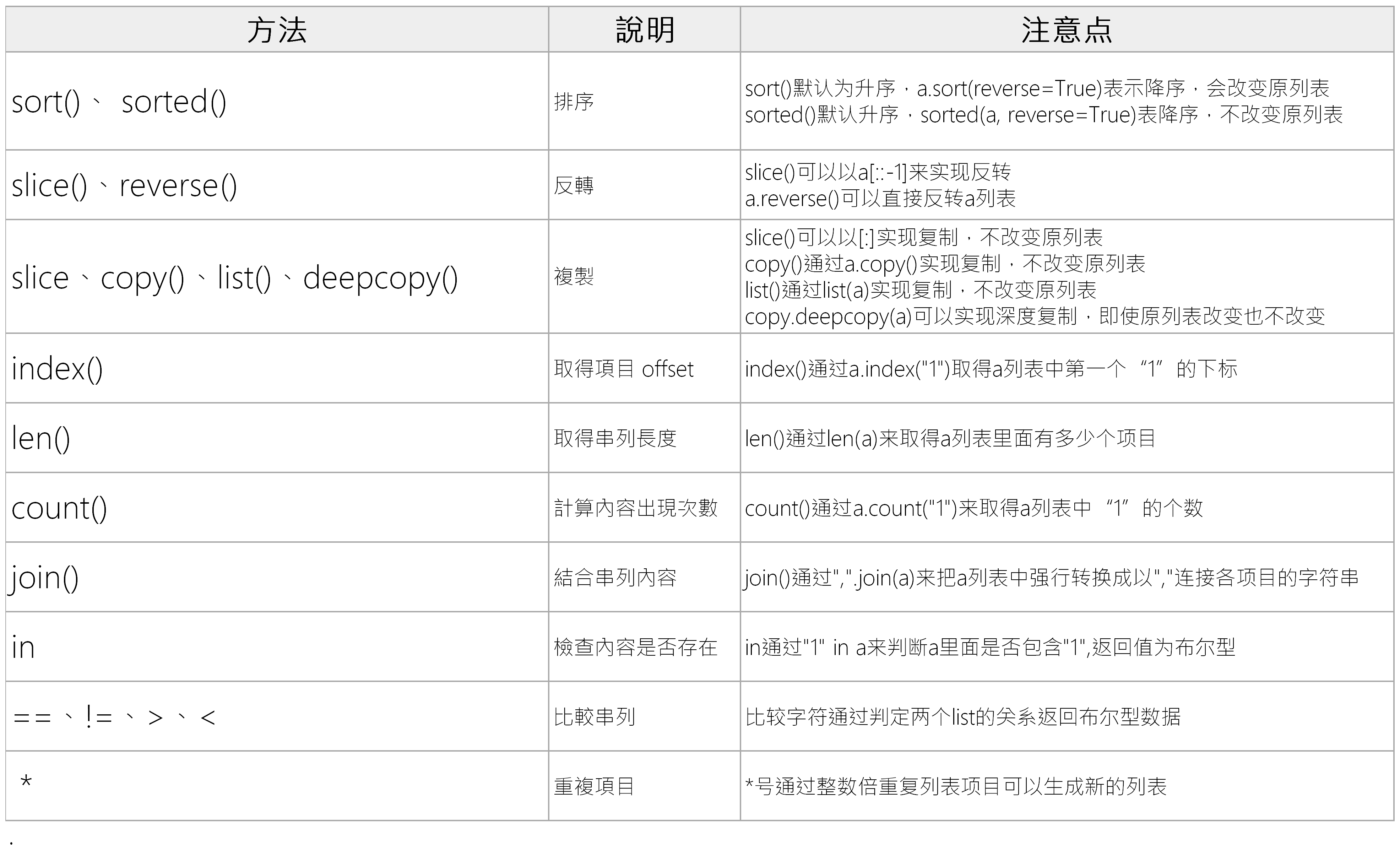
Pytho元组(tuple)
python中有两种序列结构,分别是元组(tuple)和列表(list),两种序列都可以将任何一种物件作为它们的元素,元组和列表的差异有以下几点:
1. 元组(tuple)只要建立了,便不可以修改内容
2. 元组(tuple)使用小括号,而列表使用中括号
3. 如果元组(tuple)只有一个元素,就必须在后方加上逗号,多个元素则不用
尽管元组在使用上不会像列表那样灵活,但是元组也有其好处
1. 元组读取速度比列表快
2. 元组占用空间小
3. 元组资料更安全(因为其建立后无法被更改)
建立元组有两种方法,可以通过小括号和逗号建立,也可以通过tuple()函数来转换建立,注意,元组只有一个元素时,元素后必须跟逗号,若是转换单个元素则会自动补全逗号,如下为建立元组范例
a=(1,) #直接建立元组a,因只有一个元素,所以必须在元素后方添加逗号,否则其数据会直接声明成那个元素而非元组
b=tuple(["hello"]) #使用tuple()函数转换数据为元组,会自动补全逗号要读取元组中的类容,我们有两种方法,一种是使用变量读取,一种是使用下标(offset)读取,
使用变量读取就是将元素赋值给元素数量个变量,下标就是索引读取,如下范例
x,y,z=(1,2,3) #1,2,3将分别赋值给x,y,z,注意一定是元素个数的变量,可用len(元组)得到数量
a=(1,2,3)
x=a[0] #读取了a元组的第一个元素并赋值给x值得一提的是要拼接元组也可以是使用加号(+)拼接多个元组,*也可以让元组重复扩充倍数,若一定要修改元组的元素,则可以先将其转换成list,然后添加元素后再转换成元组
Python字典(dictionary )
python中的字典和列表相似,都能作为存储资料的容器,顾名思义字典就是有查询字典对应值的功能,所以字典的每一个元素都具备 键(key):值(value),使用频率很高,多用于索引值和web API的传输,注意字典是无序的,是按照key来进行索引
建立字典有两种方法,一种是直接用{}包含键值,另一种是dict(键=值)来转换,范例如下
print({"name":"ric" , "age":28}) #使用了{}包含键值的方式建立字典,可以为空
print(dict(name="ric" , age = 28)) #使用dict((键=值)来转换成字典
print(dict([["name","ric"],["age",28]])) #使用了dict()转换成对的list生成字典
print(dict(['ab','cd','ef'])) #当list内是双字符串的时候也可以被转化读取字典的时候需要知道键(key),格式为 dic["key"]去读dic字典中的"key"的值,也可以使用dic.get("key")来读取,范例如下
a={"name":"ric" , "age":28}
print(a["name"]) #使用key标读取值
print(a.get("name")) #使用get()函数读取值要修改字典可以通过dic["key"]=值的方式来修改对应key的值,也可以使用setdefault() 可以写入新的键值对,如果已有这个键则不会修改,如下为范例
a={"name":"ric" , "age":28}
a["name"]="new_ric"
a.setdefault("IQ",100)
print(a)要删除字典的内容有三种方法,分别是del dic["key"]来删除单个键值,dic.pop("key")取出键值和dic.clear()来清空字典,范例如下
a={"name":"ric" , "age":28}
del a['name'] #删除a字典的"name"键
b=a.pop('name') #取出a字典的"name"键赋值给b并移除a字典的"name"键
a.clear() #清空a字典要将多个字典合并成一个字典,有两种方法,分别是{**dic1,**dic2}(**dic可以将dic字典拆为keyword arguments 列表,再通过大括号组合就结合成了新字典),另一种是dic1.update(dic2),update可以将dic2接在dic1后面,多次调用便按执行顺序拼接,如下为范例代码
a={"name":"ric" , "age":28}
b={"":"ric" , "eat":"apple"}
print({**a,**b}) #将a和b字典拆分后使用大括号结合
a.update(b) #使用update()函数将b字典更新到a字典
若要取出字典内所有的key和所有的值可以通过dic.keys()和dic.values()来读取生成list,如下范例代码
a={"name":"ric" , "age":28}
print(a.keys()) #使用dic.keys()来获取字典a的键并生成list
print(a.values()) #使用dic.values()来获取字典a的值并生成list我们可以使用 key in dic 来判断键key是否在字典dic里面,返回布尔型的值,也可以使用dic.copy()来复制(注意如果原始字典改变,那么复制的字典也会改变),也可以使用copy.deepcopy(dic)来进行深层复制,会产生一个独立的新字典,不受原字典改变的影响
Python集合(set)
集合(set)就象是只有键,没有值的字典,一个集合里所有的键都不会重复,因为集合不会包含重复性的资料的特性,常用来去重或判断元素间是否有交集等,其格式为set(要标称集合的资料),如果建立时出现重复项目,只会保留一个,如果是字典,只会保留键,范例代码如下
a=set([1,2,2,3,3,4,5]) #只保留不重复的元素
b=set("1223345") #只保留不重复的元素
c=set({"name":"ric" , "age":28}) #只保留键(key)
print(a)
print(b)
print(c)
也可以直接使用大括号{项目}来建立集合,注意如果大括号内是空的则会被认为是字典
我们可以使用 集合.add(项目)来将项目添加到集合内,也可以使用 集合.remove(项目)来移除集合中的(如果不存在项目会报错),而 集合.discard(项目)也可以移除集合中的项目,不存在项目的时候不会报错,如下为代码范例
a={1,2,3,4,5}
a.add(6) #添加6到集合a中
a.remove(1) #移除a中元素1,如果不存在1则会报错
a.discard(2) #移除a中的元素2,不存在2也不会报错集合中还存在一些方法来运算集合间的情况,如下是集合的运算方法和集合概念
 后记
后记
Python的数据类型是python如此易学和简洁的核心原因,我们需要熟记这些数据类型才能在正式的开发环境中运筹帷幄,学习之路正式起步。