
继老辛解决了梯度消失的问题之后,大家似乎找到了方向,深度学习在这几年里也出现了很多正向的事件,不过都是一些不足以改观人们的“机器不如人”看法。
AlphaGo战胜国际顶尖围棋高手
直到2016年,谷歌公司基于深度学习的AlphaGo以4:1的比分战胜了国际顶尖围棋高手李世石,瞬间让谷歌公司和深度学习成为了最顶尖的谈资,AlphaGo在后来也和多位围棋高手过招,均取得完胜,世界第一的围棋手从此变成了一位机器人,也证明了此时的深度学习已经能在特定领域中超越人类认知,机器打败了人类的顶尖围棋手正式宣告了深度学习的价值能够与人产生的价值相提并论,是深度学习爆发的象征。 AlphaGo Zero战胜AlphaGo
AlphaGo Zero战胜AlphaGo
2017年又是不同寻常的一年,这一年诞生了基于强化学习的AlphaGo Zero,与AlphaGo不同的是AlphaGo Zero真的和其名字一样从0开始自己学习,然后AlphaGo Zero就以100:0的比分打败了AlphaGo,这种巨大的差异就象是一个壮汉将一个孩子按在地上摩擦,更不用提人类最强与其差异了。
ILSVRC竞赛
其实在2012年,ImageNet(ImageNet项目于2007年由斯坦福大学华人教授李飞飞创办,目标是收集大量带有标注信息的图片数据供计算机视觉模型训练。ImageNet拥有1500万张标注过得高清图片,总共22000类,其中约有100万张标注了图片中主要物体的定位边框。每年度的ILSVRC比赛数据集中大概拥有120万张图片,以及1000类的标注,是ImageNet全部数据的一个子集。)就开始举办ImageNet Large Scale Visual Recognition Competition (ImageNet 大规模视觉识别竞赛),简称ILSVRC竞赛,当时的主流训练使用CPU,后来发现GPU对于单纯的浮点数运算有很好的性能,也就是从那时起,大家开始调用GPU来训练深度学习模型。
AlexNet(2012年ILSVRC冠军)
Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。这个版本比较厉害的地方是很有想法,一个现在常用的防止过拟合方法被提出,也就是Dropout概念,大概意思是在训练过程中,随机忽略一部分神经元的结果,而这个忽略比例也成了现在深度学习训练的其中一个超参数,这样做的结果让神经网络的产生充满了随机性,可能性也随指数增长,而因为学习率和bach size的限制,模型会一步步朝着我们期望的方向训练发展。AlexNet还使用了一些创新技术,在CNN中使用重叠的最大池化来提高特征的丰富性,使用LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,抑制反馈小的神经元,增强了模型的泛化能力。使用了Cuda来加速训练模型,还使用了数据增量(通过反转,截取,加入噪音等方式生成新数据集,主要为了防止数据过拟合,却被大家经常用来补全不足的数据类)。如果你也有训练过深度学习模型,那么会发现AlexNet的创新后来都变成了超参数内置在模型里面,Dropout的比例,CNN池化重叠数,LRN的灵敏度,cuda相关的bech size和圈数,数据增强的启用开关。AlexNet算是为后来的开发者好好的启蒙了一次,也决定了未来的发展方向。
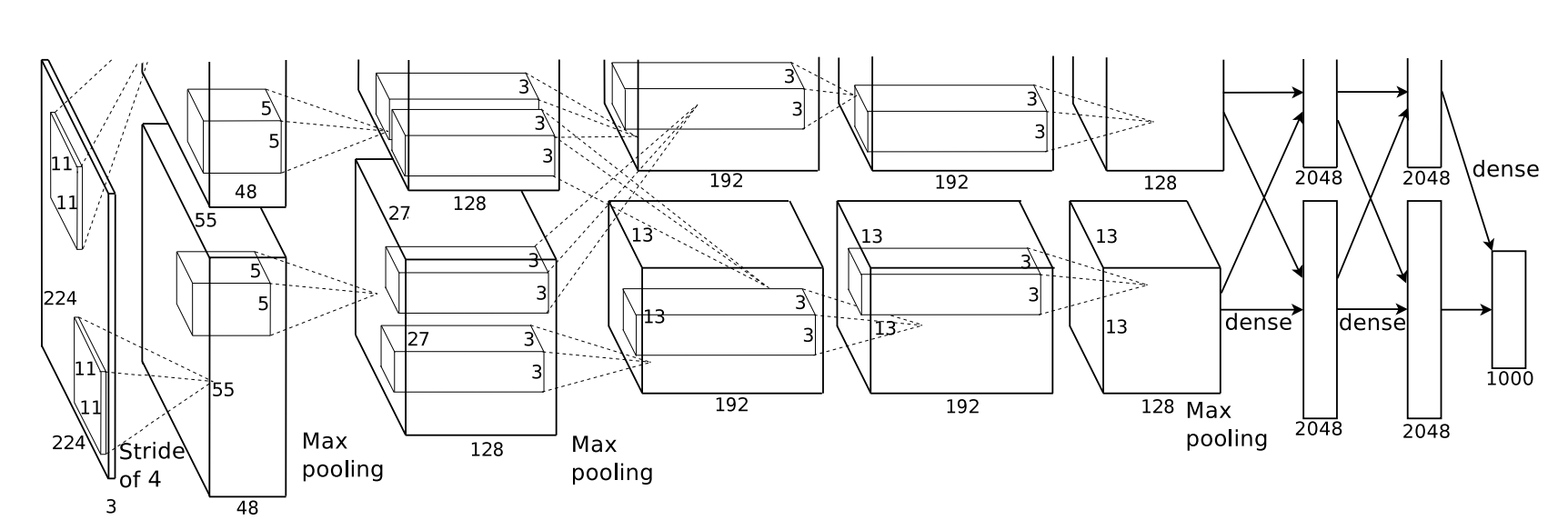 图:AlexNet网络结构
图:AlexNet网络结构
AlexNet论文地址:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
VGGNet(2014年ILSVRC定位冠军/分类亚军)
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究院一起研发的深度卷积神经网络。受到AlexNet的启发,卷积神经网络开始萌芽并发挥强大的能量,VGGNet又使用了很多开创性的方法,首先是使用了ReLU作为激活函数,验证结果相比传统的Sigmoid函数在更深层的模型中表现更好,解决了梯度弥散问题(梯度弥散指的是梯度消失,模型是依靠函数的导数来决定梯度的大小的,当导数为0的时候,梯度也就为0 ,模型的学习效果不会再向着深一层的方向学习,当下的模型几乎都遇到了这个问题)。VGGNet通过反复堆叠3*3的卷积核和2*2的最大池化层,成功构建了16-19层的卷积神经网络,这样的方式直到现在还被大多数的深度学习模型参考。值得一提的是VGGNet的C模型开始添加1*1的卷积层,为后来的降维提供技术原型,D模型和E模型就是我们熟知的VGGNet-16和VGGNet-19,参数没有增加但是计算量有增加。
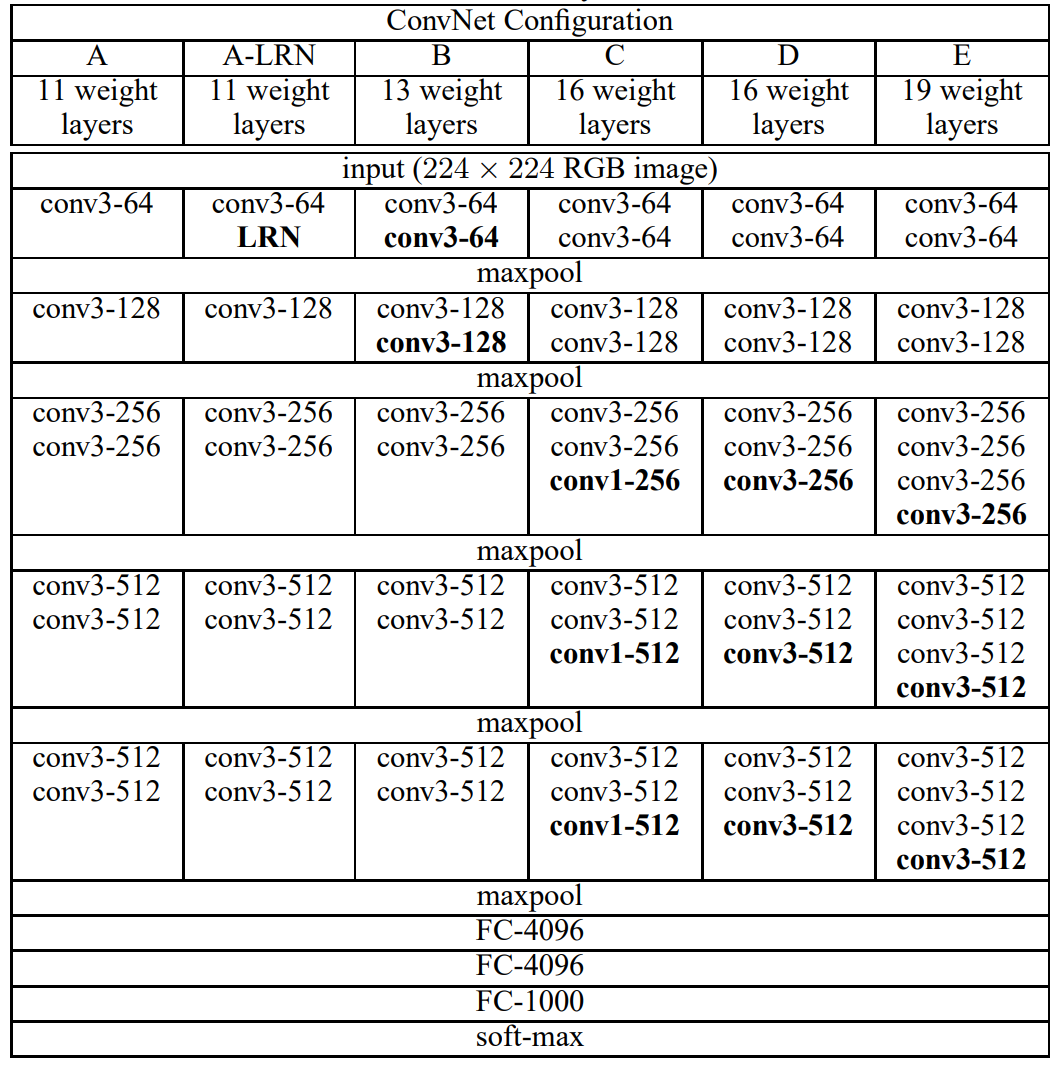 图:VGG卷积网络配置分布
图:VGG卷积网络配置分布
VGGNet论文地址:https://arxiv.org/pdf/1409.1556.pdf
Google Inception 系列网络
Google公司在发现深度学习的价值体量巨大后,积极参与深度学习的研究,代表谷歌参赛的Inception-V1(2014年ILSVRC冠军)模型更深至22层,也许很多人没有听说过,但是它有另一个广为人知的名字-GoogleNet,取消了全连接层改用全局平均池化层取代,比较精妙的是Inception-V1也采用了1*1卷积,在我们认知中并没有太大意义的1*1卷积在Inception-V1里面可以随意升高维度和降低维度,跨通道组织信息,防止过拟合等,此时的Inception-V1已经远胜于AlexNet。
谷歌公司也没有停下脚步,持续改进Inception-V1,在2015年12月,谷歌同时发布了Inception-V2和Inception-V3的论文,其中的V2提出了著名的BN层(batch normalization),这个层的作用还要从之前深度学习的诟病说起,在我们将图片输入模型之前,我们会进行预处理,使我们的图片具有某一特征(比如二值化,锐化等),但是在我们处理后进入模型的第一层时图片的这种特征大部分会被卷积处理掉,为了让我们卷积后的图片依旧具有某一特征,就需要一种批量化标准处理方式,也就是这里的batch normalization,简写BN层。这样做过后让第一次卷积过后的feature map具有‘均值为0,方差为1’的特点,进入第二个卷积层后我们能很快收敛。V3也做了一些改进,引入了Factorization into small convolutions的概念,也就是拆分大卷积(比如将3*3卷积拆分为1*3和3*1),节省了参数和运算量。V3还进行了一些结构优化。Inception V4相比于V3主要结合了微软的ResNet,错误率有再一次下降。
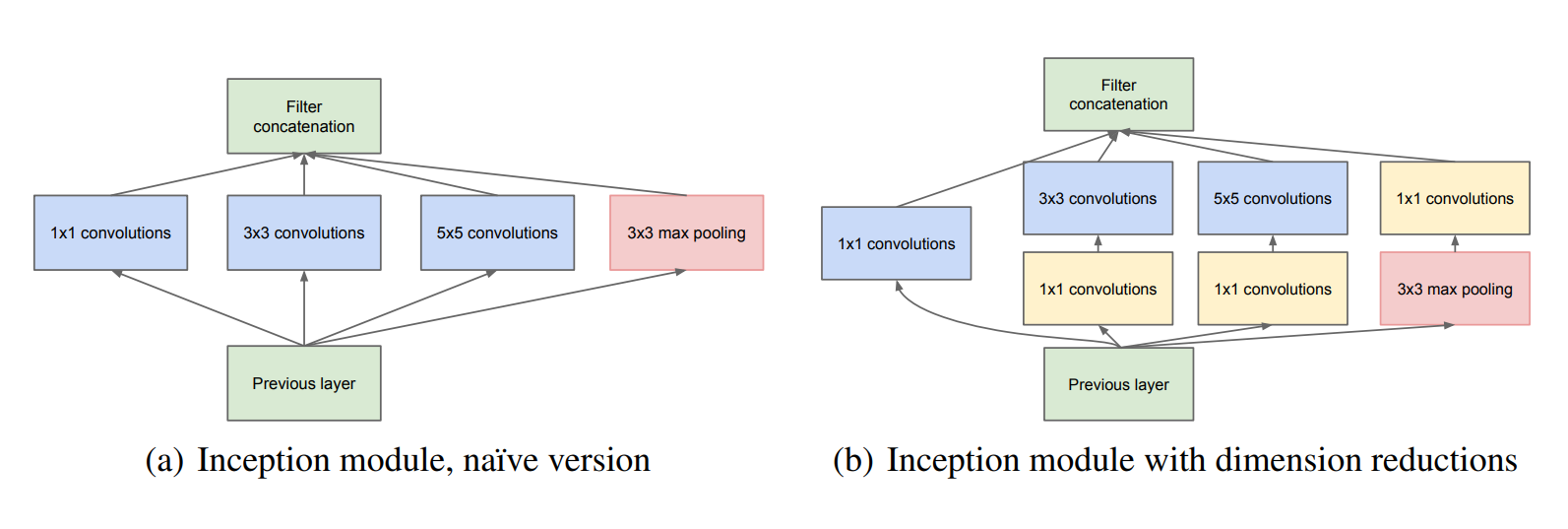
图:GoogleLeNet的初始网络
GoogleLeNet论文地址:https://arxiv.org/pdf/1409.4842v1.pdf
ResNet(2015年ILSVRC冠军)
ResNet(Residual Neural Network)是由微软研究院的Kaiming He等4名华人提出的,通过使用Residual Unit成功训练152层深的网络,ResNet中最值得玩味的是Residual Unit模块,这个模块的出现也是因为深度学习的一个诟病,在不断加深网络深度的时候,会出现一个degradation的问题,翻译过来是降解,即准确率会先上升,然后达到饱和,再继续增加深度则会导致准确率下降。听起来是不是觉得就是过拟合问题?其实研究出来并不全是,因为研究时发现随着深度增加,不仅在测试集上误差增大,在训练集上误差也持续增大,这种情况被称之为degradation问题。(如果是过拟合,则会显示成在训练集上误差减小)。理论上随着深度的增加,模型的学习能力会更强,更神的模型不应该出现这种“退化”问题,而实际情况是当模型更深时,SGD(随机梯度下降)优化时会变得困难,导致模型越深,优化越偏,当时何凯明就在研究一种规避“退化”问题的方法,也就是Residual Unit模块,源于一个灵感,就是全等映射的问题,即在准确率达到饱和的比较浅的网络后面加上几个y=x的全等映射层,起码误差不会增加,即更深的网络不会带来训练集误差上升。这样的设计让深度学即使再深入也不会降低其学习到的特征,也是现今大多数模型的方式,在模型超参数配置时有一个类似earlystop no improve in N rounds *optional的超参数(大多数会注明stop关键字),这个参数的意义就是训练多少圈模型的效能不收敛即停止训练,保留的是前一个最好的模型。这个方案也帮助google优化了Inception V4。
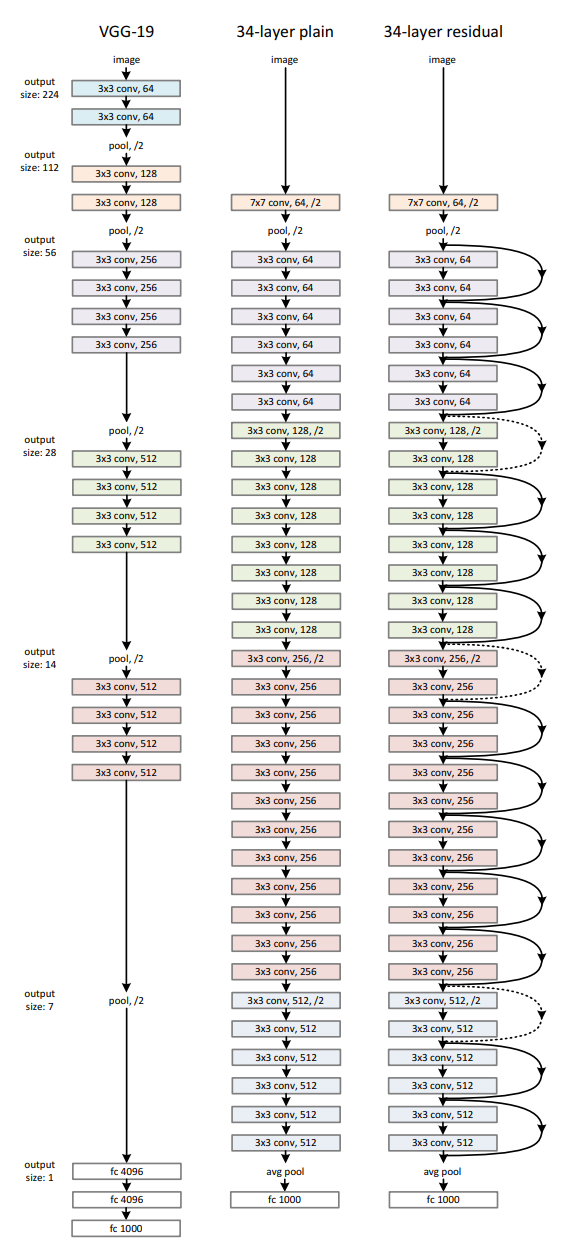 图:ResNet网络结构
图:ResNet网络结构
ResNet论文地址:https://arxiv.org/pdf/1512.03385.pdf
DenseNet(2017年CVPR best paper)
DenseNet吸取了ResNet的shortcut思想来解决训练过程中前传信号和梯度信号在经过深层学习逐渐消失的问题,增加了跨层的连接实现输入输出信息的高速流通,为了最大化网络中所有层之间的信息流,作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入,使得block中的任意两层都能够直接“沟通”。这样做的结果是解决了梯度消失的问题,可能会有小伙伴认为所有层两两连接会增加计算量,事实上这样做的时候由于大量特征重复使用,使得使用少量的卷积核就可以生成大量的特征,最终模型的尺寸也比较小。值得一提的是从ResNet开始,就有许多制造业开始使用深度学习投入正式生产环境,其后被DenseNet取代,DenseNet在很长一段时间中均被作为工业产品的辅助生产中,包括组装段产品的螺丝/接口检测,测试段的接入口判定,包装段的外观检测,均可以使用DenseNet来实现。要知道在这之前,所有的作业系统只有通过专家系统来进行辅助作业,专家系统也是人工智能的分支,但是因为其在某一个领域的深度挖掘,然后使用推理机进行延申,不过基于专家系统的机器总是需要安排大量的人工来进行调试以适配某种新型号料件的导入,甚至类似料件过多后,推理机给出的结论需要更多限定条件来赛选,每一次的导入均需要再适配现场光源和位置。相比之下的深度学习就灵活得多,我在A机器训练得模型,如果需要导入B机器,那么只需要再把B机器的数据继续A模型训练即可兼容B机器,此时新模型将兼容AB机器,灵活性和操作性提升不少。
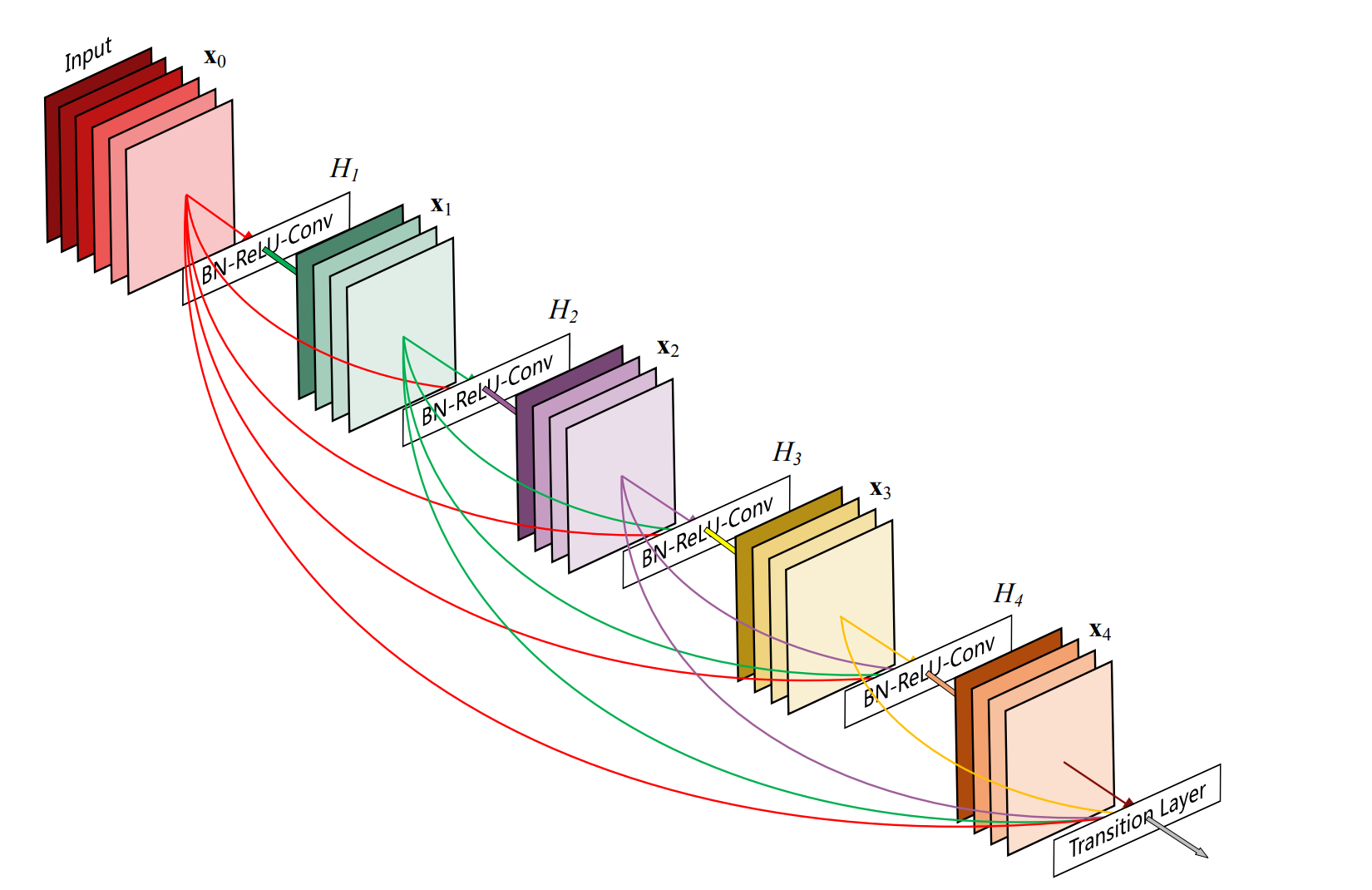 图:DenseNet网络的Block结构示意图
图:DenseNet网络的Block结构示意图
DenseNet论文地址:https://arxiv.org/pdf/1608.06993v5.pdf
深度学习大爆发
2017年过后,ILSVRC不再举办深度学习大规模视觉识别竞赛,2017年变成ILSVRC最后一届,不过也正是因为ILSVRC的影响力和引路人角色,也就是2017年,Transformer诞生,由google在论文 Attention is All you need提出,使用闻所未闻的 Self-Attention(自注意力)机制,结束了RNN的使用,相比之下 Self-Attention支持并行运算。从实际使用上说Transformer是一个NLP模型,在当时NLP大多需要包含RNN网络,但是有一个上下文联系的问题,最可能的情况是你说代词,智能助手根本不知道它/他/她到底指的是什么,而Transformer用自注意力机制成功解决了这个问题。Transformer的发布只是在各大技术圈被人谈论,当时很多厂商在2017年推出了语音助手,不知道有没有借鉴Transformer,不过接下来才是重点,继Transformer后出现了很多以Transformer为蓝本改版的模型,著名的封神模型Swin transformer便是其一。
Swin transformer大规模应用
Swin-transformer深度学习模型是2021年由微软亚洲研究院提出的一种基于Transformer的深度学习网络结构,在2022年kaggle竞赛(kaggle是全球性数据科学、机器学习竞赛和分享平台。很多大公司作为出题方,会将问题和相关数据放在平台上形成一个竞赛)中图像分类、目标检测、实例分割和语义分割竞赛中保持最领先地位.Swin-transformer使用了层级式的transformer来解决实体和像素过大的问题,可以理解为transformer是NLP类模型,文字处理不会太大,而图像则是三维的,体量相比文字是指数级增长比如一张彩色224*224的图片就变成了224*224*3=150528长度,只有拆分后来进行训练,但是拆分后训练就变成了个体,没有联系了怎么办?这就要说说Swin-transformer的滑动窗口机制,大意就是每一段拆的时候分两种形式拆,如果第一次拆的是4*4拆,那么第二次我就滑一下,先预留一个2*2过后,然后再来4*4拆,然后再把训练好的结果连起来,就是完整的信息了,然后就是继承下来的自注意力机制,可以让数据结合起来。就是如此,神级的模型诞生了,直到现在,我所在的公司还在以Swin transformer作为底层模型进行改进,各种V2版,还带CAM热力图功能,也有自动标注功能,配套了后台的数据分析系统。
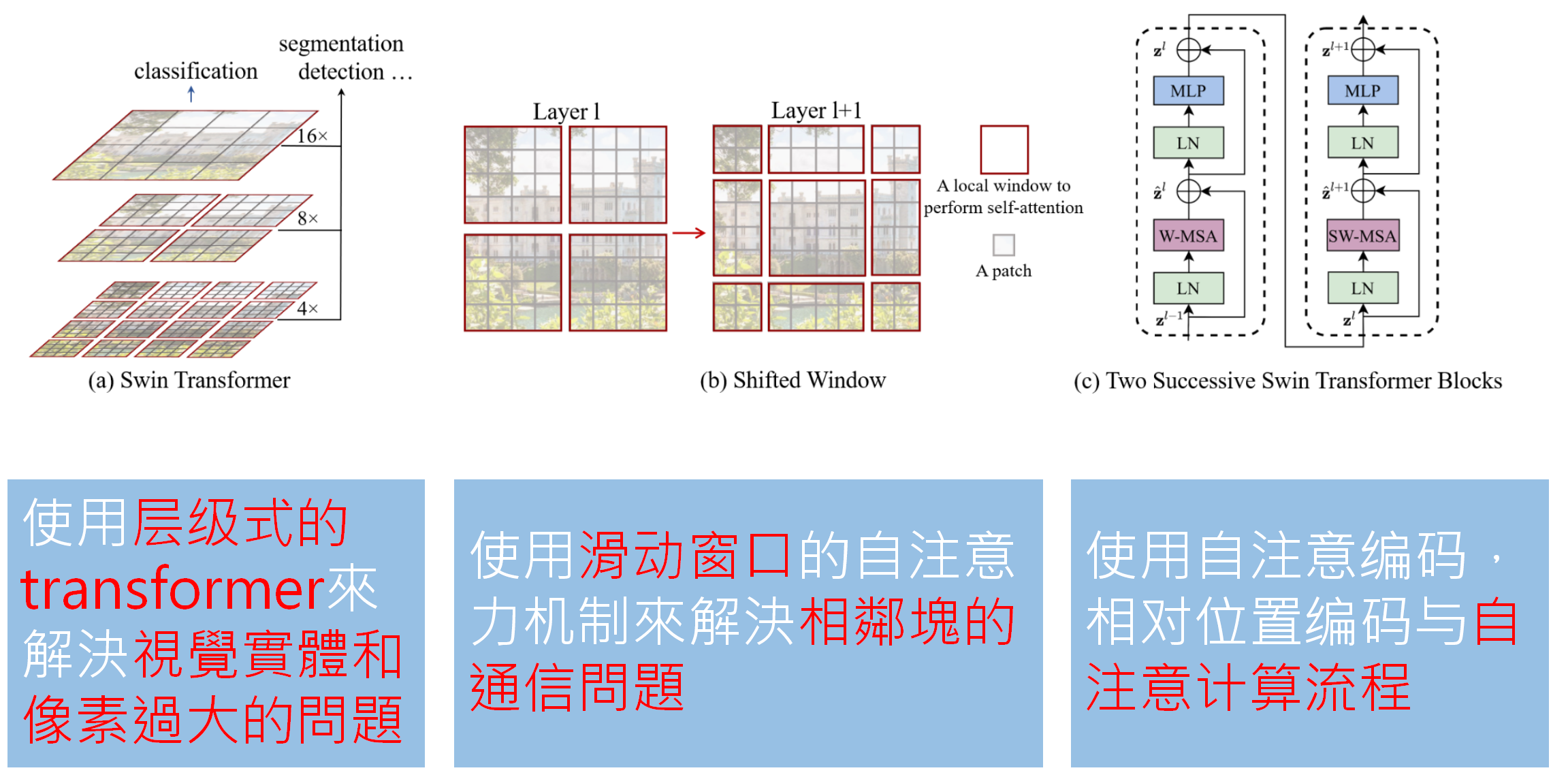 图:Swin transformer使用的关键技术
图:Swin transformer使用的关键技术
Swin transformer论文地址:https://arxiv.org/abs/2103.14030
后记
到目前,深度学习依旧在快速向前发展,分类用Swin transformer,对象检测用yolo V7,其他的诸如GAN对抗网络均有涉及,不得不说深度学习的开源为各大制造业公司创造了很好的条件,不再需要太大的专利成本,遇到解决不了的,花10W美元在kaggle上设立项目,就会有全球的深度学习工程师为你定制模型,而这笔钱也许让本公司的专业技术人员来做都不一定能达到上线的标准。我在深度学习方面也不太专精,但是需要动作操作,设定一个目标,实际架设服务器,安装各种环境,然后实际训练一个模型并试着从数据,标注,超参数,模型选用方面去优化这个模型,最后达到设定的目标后就可以继续下一个目标。